Mikolov RNNLM Thesis
这篇博客基于Mikolov大神的博士论文Statistical Language Models based on Neural Networks、相应的RNNLM(Recurrent Neural Network Language Model)公开源码以及Mikolov在google做的slide。
从Mikolov在google做的报告幻灯片来看,语言模型应该对任意词序列进行合理的评价,笼统地讲,也就是说有句法、文法意义的词序列的评价应该高于模糊的序列。
统计语言模型的评价
语言模型的质量基本通过困惑度(perplexity)和词错误率(word error rate)来进行评价:
Perplexity - 迷惑度/困惑度/混乱度
Perplexity(PPL)是对于词序列中的词而定义的:
$$ PPL = \sqrt[K]{ \prod_{i= 1}^K \frac{1}{P(wi | w{1 \cdots i-1 } ) } } = 2^{ \color{red}{ - \sum_{i=1}^K \frac{1}{K} log_2 P(wi | w{1 \cdots i-1 } ) }} $$
可以看到,打开根号以后,2的指数部分与交叉熵非常相似,因此PPL可以理解为测试集中的单词平均熵的指数放大。所以,PPL实际上是放大了交叉熵,低PPL与低熵一样,都是能清晰地传递信息的词序列。如果我们想一想语言的实质,实际上可以把语言看作一种词汇的序列,而不同的词汇之间千差万别,所以也大致上可以认为它们是离散的符号,这样想来,自然语言实际上就是离散的符号之间的一种特殊的、受语法规则限制的序列。从这个角度看,用PPL或者熵来衡量LM的质量是比较合理的。
虽然我们采用PPL来衡量LM,但是很难像解函数最值问题一样,把一个LM扔进PPL得到数值,然后通过求PPL最小值来求解最优的LM,因为这基本上不是一个数值计算的问题,特别是考虑到极其复杂的现实语言应用情况时,就更绝无希望。根据Mikolov的博士论文提及的,Solomonoff关于这方面通用的预测优化方法Algorithmic Probability (ALP)做出了相当的贡献。另一个在这部分被Mikolov提及的工作是Mahoney的,他指出对于一个数据集求解最优模型实质上等同于一个通用的数据压缩问题(general data compression)。
Word Error Rate - 词错误率
词错误率WER的定义简单得多,就是一个纯粹的比例:
$$ WER = \frac{S+D+I}{N} = \frac{Substitutions + Deletions + Insertions}{N} $$
WER是为了将N词序列 $\mathbf{W}$ 的表达变换到另一种表达 $\mathbf{W}’$ 而所需进行的替换、删除、插入操作的最小操作数量。这种衡量方法有一个显而易见的缺点,就是对于非信息词汇(uninformative words)过分强调,所以充满了噪音,而显得并不精确。而相应的,优点是只要有了参考文本,就比较容易进行计算。
n元模型 - N-grams
简单的n元语言模型通过词汇的共同出现频率(word co-occurence frequencies)来进行估计概率。在n元模型中,如果给定了合理的上下文 $ h $ 和相应单词 $ w $ ,那么单词 $ w $ 出现在 $ h $ 中的概率应该比较高。相应的,一个意思相去甚远的单词$ \check{w} $应该有比较低的概率,这实质上是一种负采样的方法。
$$ P(w|h) = \frac{C(h,w)}{C(h)} $$
词汇的共同出现频率(word co-occurence frequencies)的策略是直接进行频数 $ C(h,w) $ 和 $ C(h) $ 的统计,通过计算上下文 $ h $ 条件下出现单词 $ w $ 的条件概率 $ P(w|h) $ 即可,显然合理的词序应该具有较大的概率。这里的上下文 $h$ 也可以理解为(记忆)历史history,如果 $h = \emptyset$ ,也就是说根本不需要考虑历史情况时,那么就蜕化为1元模型。
n元模型很简洁,通用性也比较高,所以它的计算速度很快,并且比较可靠。很多更好的技术对于应用并没有带来关键性的提升,但计算资源却消耗得多的多,所以n元模型仍有其魅力。Mikolov在论文中说的这句话比较有水平:
(those better techniques) provide just marginal improvements, not critical for success of given application.
问题同样是显著的。首先一个问题是上下文的匹配问题。很多情况下,嵌入在上下文 $h$ 的单词 $w$ 应该能嵌入很多与 $h$ 类似的上下文 $\tilde{h}$ 中,但是简单模型的计算方法只是粗糙地统计了 $h$ 的情况,所以只能精确地匹配到 $h$,而缺乏泛化到 $\tilde{h}$ 的能力,也就是说无法对相似的历史记录 $ \tilde{h} $ 进行聚类。还有其他关于计算规模等性能上的问题,都是简单模型的缺陷。
上一小段提到的泛化问题会导致稀疏性的问题。可以想象,在一篇文章中,训练集中可见的单词 $w$ 的上下文/历史 $h$ 很难重复出现,所以不考虑泛化的情况时,以及没有出现在训练集中的不可见的单词 $\hat{w}$ ,对于这两种情况,概率估计都会趋于/变成零。这就会显得非常稀疏,所以需要采用一些平滑(smoothing)技术,这样就可以“管中窥豹”了。
对于稀疏性的问题,一种改进模型是让词汇分类,再基于类进行训练,是为Class Based Models. 对于一些简单的情形,模型将每个单词映射到一个简单的类集合中,然后通过类训练n元模型。显然这种分类行为在某种意义上已经干预了词向量的表达,已经有一点人为地强行聚类的意思,不像word2vec根据文本而改变词向量自身的表述,而是另开洞天分类,显然对于稀疏性问题能有较大的提升。但是这种干预的成本是比较大的,比如实用专家知识进行人工分类时,会消耗较大的人力、时间、金钱成本。更惨的是,当训练集的规模增长的时候,Class Based Models的优势也渐趋于无。
再提几个论文中提到的n元模型很难处理的语言特征:
长上下文 - long-context
比如句子 THE SKY ABOVE OUR HEADS IS BLUE 在这句话中,BLUE依赖于距离它不远的SKY。但是在其他的句子中,譬如 THE SKY THIS < MONDAY, TUESDAY, …, SUNDAY > < MORNING, AFTERNOON, EVENING > ABOVE OUR HEADS WAS BLUE,这些句子里的BLUE和SKY距离可能就有些太远了,N=4的情形已经不足以适用,而N=10的情况则会让计算量爆炸性地增长。
对于这个问题,论文中提到了一种改进模型:Cache Language Models. 它是基于这样的一种观测,比如在一片TOEFL的阅读文章中,讨论某一个专业话题时会出现许多在其他一般文章中看不到的专有词汇,这些专门词汇相对于其他通用词汇显得非常稀缺,但一旦在最近的历史中出现时,比如一篇TOEFL心理学文章中,那么在这篇文章中就有很大可能会再次出现。所以就像计算机系统的结构,引入缓存cache来改进n元模型,对PPL有很大的减少。
另一种改进策略更偏向于统计模型以前的语言学模型:Structured Language Models. 距离较远的单词在语义和语法上紧密相连的句子实在是太多了,n元模型很难应对这些情况。在Structured Language Models中,句子被视作与让下文无关的语法树,叶子节点自然是独立的单词,而中间节点是非终符号(non-terminal symbols). 与传统语言学模型不同的是,Structured Language Models在构建语法树的时候采用了统计方法,在给定语法树框架下通过训练集来计算树的概率。除了计算与稳定性能的问题以外,这类模型对于歧义ambiguity很难处理,因为一个句子不同的歧义可能对应了不同结构的语法树。
无法发现独立单词的相似性 similarity of individual words
例如 PARTY WILL BE ON < MONDAY, TUESDAY, …, SUNDAY > 这句话中,即便我们训练了MONDAY和TUESDAY的情形,n模型也无法认定FRIDAY是高概率的句子。当然,这个要看词向量之间有没有关系,如果只是采用one-hot的词向量,那么肯定会产生词汇鸿沟。如果是word2vec训练过之后的模型,自然对FRIDAY的评价不会低,但是这样就有点本末倒置了。。。
为了克服n元模型的缺陷,Mikolov在论文Statistical Language Models based on Neural Networks中除了提到上面集中改进以外,主要论述了和标题一样的语言模型:基于神经网络的统计语言模型。这个语言模型主要解决的就是“n元模型的上下文/历史窗口变大时,计算量指数性地增长”这个问题。神经网络之所以比一般的n元模型更优秀,主要就是对于历史记忆的处理更加神奇。n元模型的历史是精确的n-1个单词的序列,但RNN将这部分记忆放在隐藏层中,并且把稀疏的RNN记忆隐藏层 $ h $ 射影到低维的连续空间,并且使 $ h $ 和 $ \tilde{h} $ 能够聚类,于是并不需要精确地匹配历史记忆 $ h $ ;另外由于RNN的矩阵和偏置向量是共享参数的,所以RNNLM只需要从训练集中训练较少的数据,从而模型具有较高的鲁棒性。
RNNLM - Recurrent Neural Network Language Model
RNNLM相对于Bengio提出的Feedforward NNLM的特点在于历史记忆的表达:在Feedforward NNLM中,历史仍然像n元模型一样是之前出现的若干单词,而在RNNLM中,历史的从数据集的训练中学习得到的。RNN的隐藏层不仅表现了前 $n-1$ 个单词的历史,而是之前所有的历史,因此理论上讲RNNLM可以克服长上下文单词之间的关联。
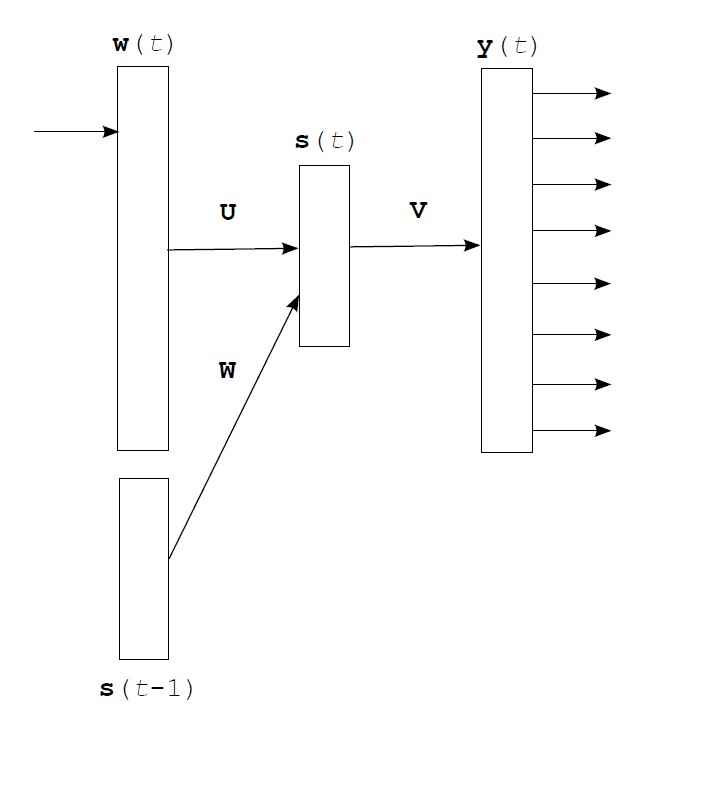
其中输入值 $w$ 的维数与词汇集中词汇的数量相同 $ dim(\mathbf{w}) = |\mathbf{V}| $ 大约在10K-200K量级,非常稀疏;隐层的规模要小很多,大约有50-1000个神经元左右; $\mathbf{U}$ 、 $\mathbf{V}$ 、 $\mathbf{W}$ 三个矩阵的形状按照线性变化而定。如果不使用 $\mathbf{W}$ 矩阵,也就是将RNN展开,那么神经网络的规模将会相当的大。
RNN训练中的计算:
$$ \mathbf{s}(t) = f(\mathbf{U} \cdot \mathbf{w}(t) + \mathbf{W} \cdot \mathbf{s}(t-1) ) $$
$$ s_j(t) = f( \sum_i wi(t) \cdot u{ji} + \sum_l sl(t-1) \cdot w{jl} ) $$
$$ \mathbf{y}(t) = g(\mathbf{V} \cdot \mathbf{s}(t) ) $$
$$ y_k(t) = g( \sum_j sj(t) \cdot v{kj} ) $$
其中对输出层采用softmax函数进行激活,以确保输出的概率满足归一化与大于零的条件:
$$ f( x ) = sigmoid( x ) = \frac{1}{ 1 + e^{- x } } \ , \ g( x_k ) = softmax( x_k ) = \frac{ e^{ xk } }{ \sum{i} e^{ x_i } } $$
模型训练采用随机梯度算法(SGD)。最初用比较小的随机数给 $\mathbf{U}$ 、 $\mathbf{V}$ 、 $\mathbf{W}$ 三个矩阵赋值,Mikolov提到在实验中使用平均数0、方差0.1的正态分布进行赋值。每训练一个单词,将 $\mathbf{U}$ 、 $\mathbf{V}$ 、 $\mathbf{W}$ 三个矩阵的参数更新一次。大致上训练的过程如下:
t = 0 # set time counter
Initialize( s[t], 1 ) # initialize the state of the neurons in hidden layer s[t] to 1
while Processed() == True: # if not all training examples were processed
t += 1
w[t] = Present( word[t] ) # present at the input layer w[t] the current word word[t]
Copy( s[t-1], w[t] ) # copy the state of the hidden layer s[t-1] to the input layer
s[t], y[t] = Forward() # perform forward pass to obtain s[t] and y[t]
e[t] = Gradient_Error( y[t] ) # compute gradient of error e[t] in the output layer
Back_Propagate()
误差反向传播
误差估计方面采用交叉熵估计输出层中的误差向量 $\mathbf{e}_o (t) $ 的梯度:
$$ Error = CE( \mathbf{y}(t) ) = \suml \log y{l}(t) = \sum_l \log \left ( \frac{ e^{ \theta_l} }{ \sum e^{ \theta_i } } \right ) = \sum_l \left ( \theta_l - \log \sum e^{ \theta_i } \right ) $$
其中$l$是正确预测的样本序数。由于采用one-hot表示,所以在做向量内积时,只需要将最终的正确分量累加即可。
因为计算输出层概率的时候采用了softmax激活函数,所以交叉熵中的对数部分会使softmax的上下指数分离出来。如果词向量 $\mathbf{w}(t)$ 预测得很好,那么它的结果 $\mathbf{w}(t+1)$ 与真正的目标向量 $\mathbf{d}(t)$ ,这两个one-hot编码的向量将会吻合。并且,因为one-hot编码与交叉熵分离softmax的分子分母,所以误差梯度有:
$$ \mathbf{e}_o(t) = \frac{d CE(\mathbf{y})}{ d \mathbf{V} \cdot \mathbf{s}(t) } = \frac{d CE(softmax(\mathbf{\theta}))}{ d \mathbf{\theta} } = \mathbf{d}(t) - \mathbf{y}(t) $$
对于上式,如果固定变量 $s(t)$ ,则可以计算 $\mathbf{V}$ 矩阵的更新值:
$$ \mathbf{e}_o(t) = \mathbf{d}(t) - \mathbf{y}(t) = \frac{d CE(\mathbf{y})}{ d \mathbf{V} \cdot \mathbf{s}(t) } \ , \ \frac{d CE(\mathbf{y})}{ d \mathbf{V} } = \mathbf{s}(t) \cdot \mathbf{e}_o(t)^T $$
可见,$\mathbf{s}(t) \cdot \mathbf{e}_o(t)^T$ 实际上是数值 $CE(\mathbf{y}) \in \mathbb{R} $ 对矩阵变量 $\mathbf{V}$ 的Jacobian矩阵:
$$ \mathbf{s}(t) \cdot \mathbf{e}o(t)^T = \frac{d CE(\mathbf{y})}{ d \mathbf{V} } =
\begin{bmatrix}
\frac{\partial CE}{\partial v{11}} & \cdots & \frac{\partial CE}{\partial v{1N}} \
\vdots & \ddots & \vdots \
\frac{\partial CE}{\partial v{M1}} & \cdots & \frac{\partial CE}{\partial v_{MN}}
\end{bmatrix}
$$
$$ \mathbf{V}(t+1) = \mathbf{V}(t) + \mathbf{s}(t) \cdot \mathbf{e}_o(t)^T \cdot \alpha $$
$$ v{jk}(t+1) = v{jk}(t) + s{j}(t) \cdot e{ok}(t) \cdot \alpha $$
$j$ 遍历了隐藏层,$k$ 遍历了输出层, $sj(t)$ 是隐藏层中的第 $j$ 个神经元的输出,$e{ok}(t)$ 是输出层第 $k$ 个神经元的误差梯度。学习率Learning Rate 是标量 $\alpha \in \mathbb{R}$,也可以看做一个微小增量,通过Jacobian矩阵变换到正确的梯度增量方向。
接着与上一个步骤刚好相反,这次固定矩阵 $\mathbf{V}$,计算交叉熵对隐藏层的Jacobian矩阵:
$$ \frac{d CE(\mathbf{y})}{ d \mathbf{s}(t) } = \mathbf{e}_o(t)^T \cdot \mathbf{V} = \frac{d CE(\mathbf{y})}{ d simoid(\mathbf{\varphi}) } $$
计算隐藏层的误差梯度 $\mathbf{e}_h(t)$ :
$$ \mathbf{e}_h(t) = d_h( \mathbf{e}_o(t)^T \cdot \mathbf{V}, t ) = d_h( \frac{d CE(\mathbf{y})}{ d sigmoid(\mathbf{\varphi}) }, t ) $$
$$ d_{h,j}( \frac{d CE(\mathbf{y})}{ d sigmoid(\mathbf{\varphi}) }, t ) = \frac{d CE(\mathbf{y})}{ d sigmoid(\mathbf{\varphi}) } \times s_j(t) \cdot ( 1 - s_j(t) ) \ = \frac{d CE(\mathbf{y})}{ d sigmoid(\mathbf{\varphi}) } \cdot \left ( \frac{d sigmoid(\mathbf{\varphi})}{ d \mathbf{\varphi} } \right ) _j $$
总之,隐藏层的梯度:
$$ \mathbf{e}_h(t) = \frac{d CE(\mathbf{y})}{ d sigmoid(\mathbf{\varphi}) } \cdot \frac{d sigmoid(\mathbf{\varphi})}{ d \mathbf{\varphi} } = \frac{d CE(\mathbf{y})}{ d \mathbf{\varphi} } $$
再更新 $\mathbf{U}$ 矩阵的值,推导与$\mathbf{V}$ 的情况一样,只是固定的变量多了一些,有 $\mathbf{w}(t) \ , \ \mathbf{W} \ , \ \mathbf{s}(t-1) $ :
$$ \mathbf{U}(t+1) = \mathbf{U}(t) + w(t) \cdot \mathbf{e}_h(t)^T \cdot \alpha $$
$$ u{ij}(t+1) = u{ij}(t) + wi(t) \cdot e{hj}(t)^T \cdot \alpha $$
矩阵 $\mathbf{W}$ 也一样:
$$ \mathbf{W}(t+1) = \mathbf{W}(t) + \mathbf{s}(t-1) \cdot \mathbf{e}_h(t)^T \cdot \alpha $$
$$ w{lj}(t+1) = w{lj}(t) + sl (t-1) \cdot e{hj}(t) \cdot \alpha $$
实用的训练建议
训练有多种选择。在处理训练的例子时,可以每次处理都把神经网络展开,但这样会带来很大的复杂度 $T \times |\mathbb{W}|$ ,其中 $T$ 是展开的次数,也就是回溯的次数,$|\mathbb{W}|$ 是每次训练的词汇数量。如果采用mini-batch的方式来处理,比如说每训练10-20个例子之后更新一次参数值,那么计算复杂度就可以消除 $T$ 的影响了。
使用双精度的实数以及一些正则化方法(regularization)会有助于提高数值的稳定性,以免因为舍入等等发生一些莫名其妙的计算问题。然而Mikolov说,在他们的实验中没有实用正则化,也没有实用L2惩罚。。。还有RNN的训练在极少数的某些情况下在BPTT训练中会指数爆炸,Mikolov在实验中采用的方法是限制误差梯度的最大值 $|\mathbf{e}| \in (-15, 15) $,这样的限制对于巨大的数据集而言是健康的。
NNLMs的一些扩展 - Extensions
舍去词汇 - Vocabulary Truncation
对于NNLMs相当现实的问题就是计算复杂度,大规模运算的代价会相当的高。计算次数基本上都以 $|\mathbb{H} \times \mathbb{V}|$ 为单位, $|\mathbb{H}|$ 是隐藏层的神经元数量,大规模的话大概有200个,词汇集的量就相当大了, $|\mathbb{V}| = 50K$ 也是不过分的。这样一来,计算时间就非常受词汇集大小的影响。所以为了提升性能,Bengio曾把所有不频繁出现的词汇扔到一个特殊的类中,并且根据他们的频率指派概率。 这样的处理是通过牺牲准确性来提升速度的。
分解输出层 - Factorization of the Output Layer
因为这部分内容在代码中也出现,具体在./rnnlmlib.cpp void CRnnLM::initNet() 函数中有涉及,所以给出比较详细的讨论。
更sophisticated的方法是分解输出层。就像之前说的,如果对单词采用one-hot编码,那么向量空间的维度也将达到词汇量级别 $|\mathbb{V}|$ ,可以轻易突破100K。这样带来的计算复杂度很高,所以对单词进行分组是一种更好的措施。将单词分到一个具体的“类”中,以组为对象计算概率,而不是对全部词汇量,在组级别上计算概率分布,可以让计算变得更加简单。
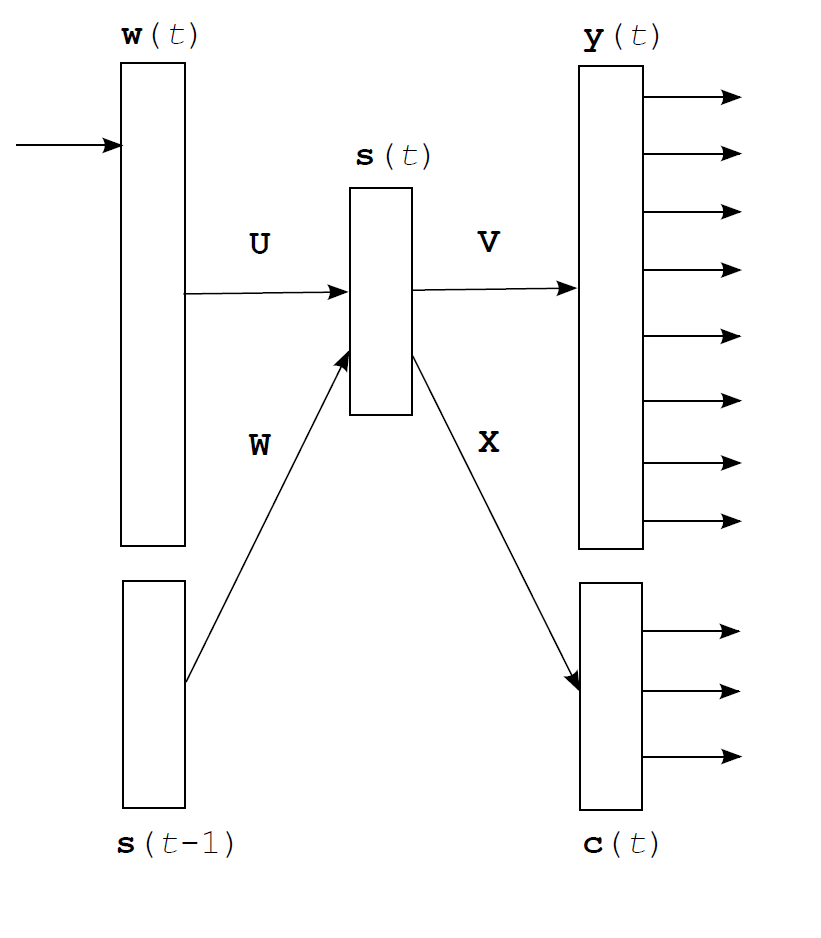
Mikolov在论文中提到,这个点子可以追溯到Goodman在加速ME模型中使用的“类” - class. 看上面的图示:首先所有class的概率分布需要计算; 然后计算某个单词属于哪一个class的概率分布;在此基础上,并不需要计算全部 $ |\mathbb{V}| $ 的元素再对它们做softmax,只需要计算 $ |\mathbb{C}| + |\mathbb{V’}| $ ,也就是只要做类量级(根据设定,为常量)以及类中词汇量级的计算就够了。
Mikolov在论文中提出了一个算法,基于1元模型中的词汇频率来给word指派class,也就是./rnnlmlib.cpp void CRnnLM::initNet() 函数中涉及的算法。这部分指派class的运算在训练以前完成,并且只基于相对频率关系,所以可以被认为是“频率装箱”(frequency binning)频率装箱/分级具体是如何实现的可以直接看代码部分的博客,注释中有提到. 这样的处理会使每一个特定的class中的单词量并不大,所以高频的 $ |\mathbb{V’}| $ 并不大,但是低频的单词依然会使 $ |\mathbb{V’}| $ 比较大。根据Mikolov的说法,通过分类优化大概可以把速度提高到100倍以上,但是模型的准确度会降低5-10%左右。
具体而言,这部分算法是这样的:
因为采用了class,所以从隐藏层到输出层的计算变成了从隐藏层到class层 以及 隐藏层到输出层的分类子集:
$$ cm (t) = g \left ( \sum{j} sj (t) \cdot x{mj} \right) = softmax \left ( \sum_{j} sj (t) \cdot x{mj} \right) = softmax( \mathbf{X} \cdot \mathbf{s}(t) ) $$
$$ y{ \mathbb{V’} } (t) = softmax \left( \sum{j} sj (t) \cdot v{\mathbb{V’}j} \right) = softmax( \mathbf{V} \cdot \mathbf{s}(t) ) $$
这样从class的角度看,单词 $ w(t+1) $ 的条件概率计算就是:
$$ P(w_{t+1} | \mathbf{s}(t) ) = P( c_i | \mathbf{s}(t) ) \cdot P( w_i | c_i, \mathbf{s}(t) ) $$
其中 $ w_i $ 是被预测的词,而$ c_i $是它的class.
也就是说先从隐藏层预测到class,再根据隐藏层、class一起决定。
前向传播就像上面的计算一样进行,但误差反向传播的时候,计算误差梯度时既需要计算word部分,也需要计算class的部分,反向传播到隐藏层的时候误差梯度需要加总。也就是说,训练隐藏层既能预测word也能预测class的概率分布。
最大熵模型 - Maximum Entropy
宏观来看,ME模型是一个直接将输入层线性变换到输出层的矩阵。这个模型的Motivation是因为训练数据集很大时,隐藏层也不得不随之增加,所以采用Joint Training With Maximum Entropy Model进行训练,可以将隐藏层的规模控制得很小。Mikolov在google展示了基于散列的Hash Based Maximum Entropy Model。
Hash Based Maximum Entropy Model主要是直接将n元的隐藏层的所有可能情况当作一个散列表来看,这个隐藏层散列表关联一个输出结果:
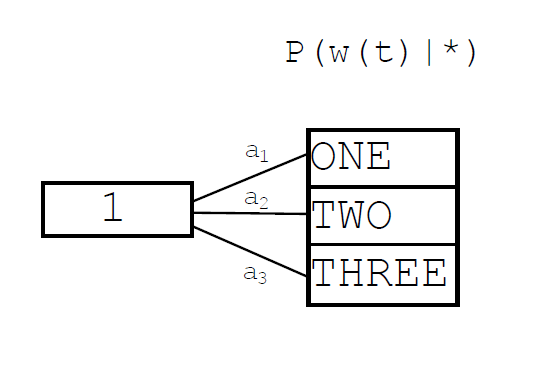
1元模型,而非0元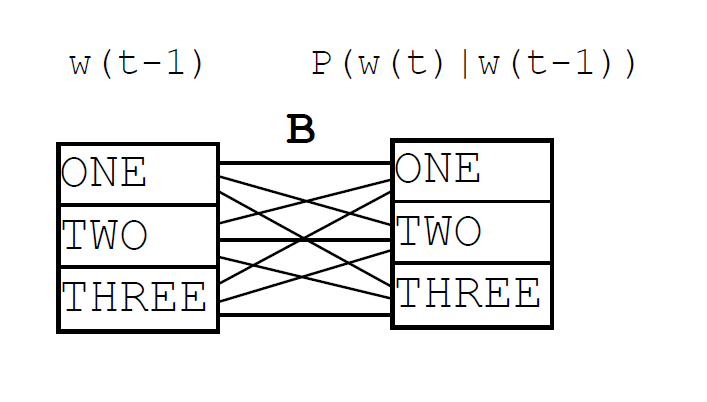
2元模型,而非1元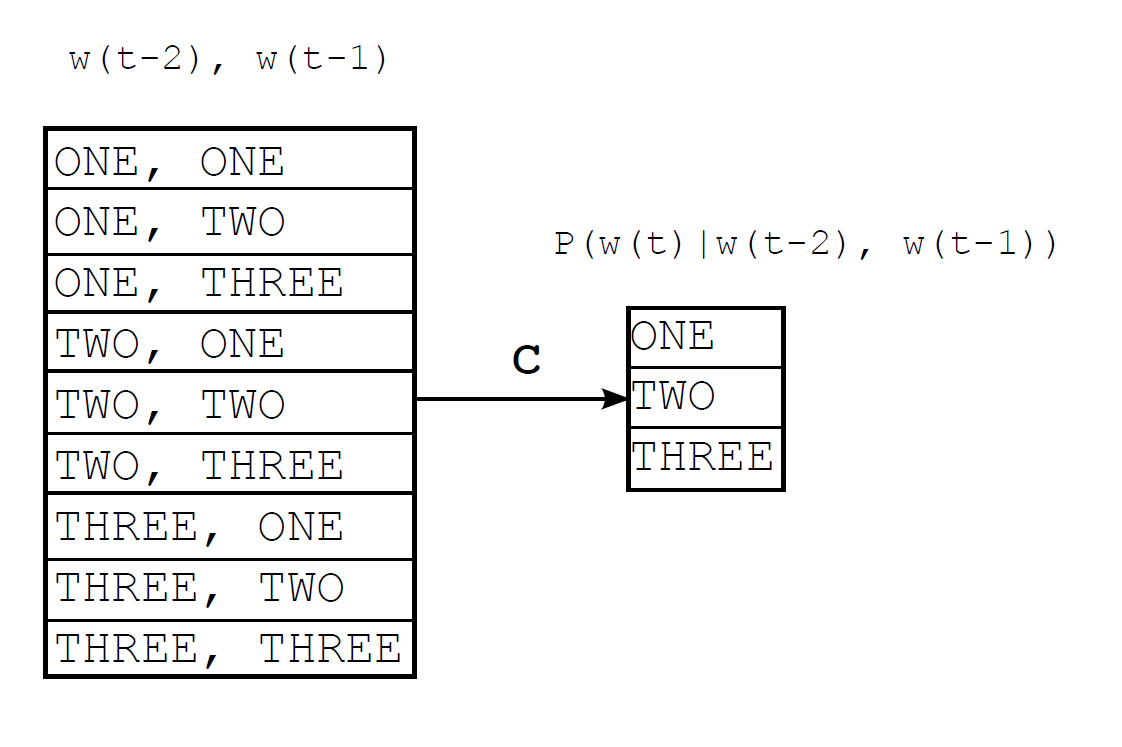
3元模型,而非2元
以上三幅图都是google的slide中的图。需要注意的是,三幅图分别对应的是1元、2元、3元模型,而非0元、1元、2元模型,因为在这个模型中隐藏层被设定为 $n-1$ 的维度,而Hash Based Maximum Entropy Model将这 $n-1$ 元的隐藏层记忆直接通过散列函数关联到一个词向量,通过这种方式避免了过大的记忆复杂度与隐藏层矩阵运算,因此SGD训练将会简单许多。
可以看到,对于一个使用了全部 $n$ 元的语言模型,每一隐藏元参数可以取遍词汇集中的任一单词,所以散列的参数情况一共有 $|\mathbb{V}|^n$ 种。而采用了hash的Hash Based Maximum Entropy Model则可以认为是一个精简的$n$ 元语言模型(pruned n-gram model).