Mikolov RNNLM Code
这篇博客基于Mikolov大神的博士论文Statistical Language Models based on Neural Networks、相应的RNNLM(Recurrent Neural Network Language Model)公开源码以及Mikolov在google做的slide。
另外,得益于国内前辈们的工作,才不至于筚路蓝缕、以启山林。已经有过源码的分析解读,这篇博客也只能在此基础上想想有什么能添砖加瓦的了。
代码版本 - rnnlm-0.4b
rnnlmlib.h
一些主要的宏定义
/* 防止 _RNNLMLIB_H_ 被重复include */ #ifndef _RNNLMLIB_H_ #define _RNNLMLIB_H_ /* 字符串长度的限制 */ #define MAX_STRING 100 /* 防止 WEIGHTTYPE 被重复include 设定RNNLM中的权值值为double类型,正是论文中 到的一些实用的建议 */ #ifndef WEIGHTTYPE #define WEIGHTTYPE double #endif
神经网络数据类型的一些设定
/* 权值设定
定义了神经元的激活值权值类型为 real,最大熵
中输入层直接到输出层的权值类型为 direct_t
*/
typedef WEIGHTTYPE real; // NN weights
typedef WEIGHTTYPE direct_t; // ME weights
/* ac是神经元中的激活值,er为误差值 */
struct neuron {
real ac; //actual value stored in neuron
real er; //error value in neuron, used by learning algorithm
};
/* 突触,非常形象,是一个神经元细胞连接另一个神经元
细胞的组织。
实际上就是一个 real(double) 类型的浮点数。
*/
struct synapse {
real weight; //weight of synapse
};
关于neuron, synapse 的初始化与赋值情况,在 rnnlmlib.cpp 的初始化函数中
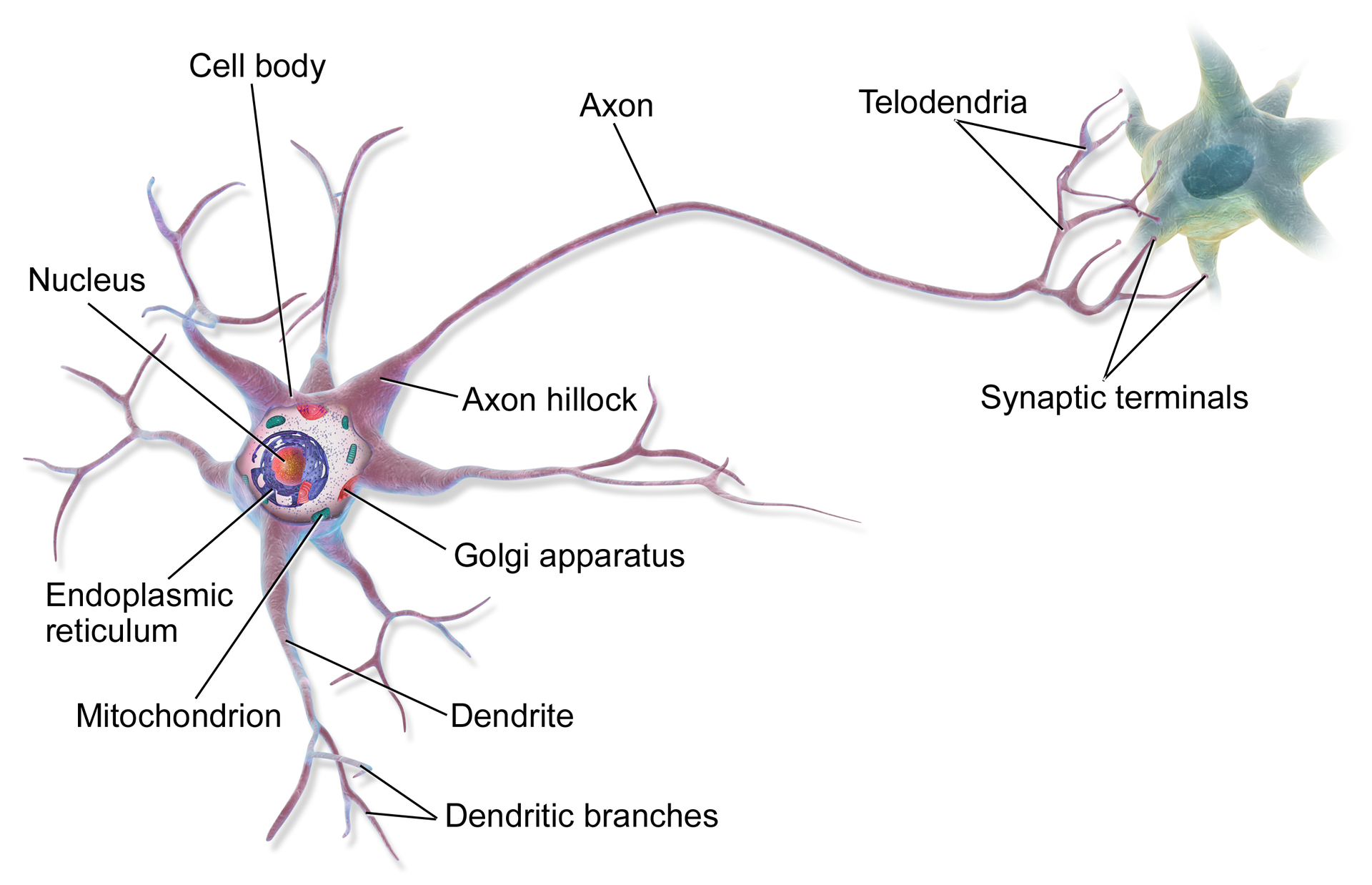
一个神经元细胞
void CRnnLM::initNet()
{
/* skip */
neu0=(struct neuron *)calloc(layer0_size, sizeof(struct neuron));
/* 神经元的初始化,相应的,还有 neu1, neuc, neu2, skip */
syn0=(struct synapse *)calloc(layer0_size*layer1_size, sizeof(struct synapse));
if (layerc_size==0) // 如果压缩层大小为零
syn1=(struct synapse *)calloc(layer1_size*layer2_size, sizeof(struct synapse));
else { // 压缩层大小非零
syn1=(struct synapse *)calloc(layer1_size*layerc_size, sizeof(struct synapse));
sync=(struct synapse *)calloc(layerc_size*layer2_size, sizeof(struct synapse));
}
/* 内存分配的管理,skip */
neu0b=(struct neuron *)calloc(layer0_size, sizeof(struct neuron));
/* 神经元的初始化,相应的,还有 neu1b, neucb, neu1b2, neu2b
和第一组神经元不同之处在于"b",所以是做back备份之用,在
函数 void CRnnLM::saveWeights() 和 void CRnnLM::restoreWeights()
中使用
在CRnnLM类定义的最后几个成员变量里有提及
*/
syn0b=(struct synapse *)calloc(layer0_size*layer1_size, sizeof(struct synapse));
/* 同上, skip */
for (a=0; a < layer0_size; a++) {
neu0[a].ac=0;
neu0[a].er=0;
}
/* 对一系列神经元的赋值,ac 与 er 都赋值为零, skip */
for (b=0; b < layer1_size; b++)
for (a=0; a < layer0_size; a++) {
syn0[a+b*layer0_size].weight=random(-0.1, 0.1)+random(-0.1, 0.1)+random(-0.1, 0.1);
}
/* 对突触的赋值,例如对 layer0 的第 a 个神经元 到
layer1 的第 b 个神经元 之间的突触赋值,突触的
序数就为 a+b*layer0_size ,即在矩阵[b行, a列]中
按行优先的方式储存,并随机赋值。
为什么采用三个 random(-0.1, 0.1) 相加,我也不是
很懂。
*/
/* bptt的初始化, skip */
saveWeights();
/* 备份 neu 和 syn 的数据到 neub 和 synb */
}
回到 rnnlmlib.h
/* word的结构定义 */
struct vocab_word {
/* 表示该词在train_file中出现的频数 */
int cn;
/* 作为字符串的单词,字符串长度有限制 */
char word[MAX_STRING];
/* 单词的概率 */
real prob;
/* 单词的类别 */
int class_index;
};
/* 储存质数的数组,用来做hash函数 */
const unsigned int PRIMES[]={108641969, 116049371, 125925907,
133333309, 145678979, 175308587, 197530793, 234567803,
251851741, 264197411, 330864029, 399999781, 407407183,
459258997, 479012069, 545678687, 560493491, 607407037,
629629243, 656789717, 716048933, 718518067, 725925469,
733332871, 753085943, 755555077, 782715551, 790122953,
812345159, 814814293, 893826581, 923456189, 940740127,
953085797, 985184539, 990122807};
/* 质数数组 PRIMES[] 的元素个数 */
const unsigned int PRIMES_SIZE=sizeof(PRIMES)/sizeof(PRIMES[0]);
/* 最大阶数,用来限制ME模型的N元模型的N */
const int MAX_NGRAM_ORDER=20;
/* 文件储存类型:
TEXT - ASCII储存,在储存网络权值时比较浪费空间
BINARY - 二进制储存,不利于阅读
*/
enum FileTypeEnum {TEXT, BINARY, COMPRESSED};
//COMPRESSED not yet implemented
类 CRnnLM 的成员变量设定及其在构造函数中的赋值
class CRnnLM{
protected:
/* 训练集、验证集、测试集、储存文件、其他模型的生成文件
{train, valid, test, rnnlm}_file[0] = 0
*/
char train_file[MAX_STRING];
char valid_file[MAX_STRING];
char test_file[MAX_STRING];
char rnnlm_file[MAX_STRING];
char lmprob_file[MAX_STRING];
/* 随机数种子
构造函数中 = 1
*/
int rand_seed;
/* 不同的debug_mode输出不同详细程度的信息
构造函数中 = 0 输出比较简略的debug信息
*/
int debug_mode;
/* rnn toolkit 版本号 构造函数中 = 10 */
int version;
/* 储存模型参数的文件类型 TEXT/BINARY
构造函数中 = TEXT
*/
int filetype;
/* user_lmprob == 1 使用其他LM
构造函数中 = 0,也就是使用RNN
*/
int use_lmprob;
/* user_lmprob == 1 时其他LM与RNN的插值系数
构造函数中 = 0.75
*/
real lambda;
/* 防止梯度爆炸的截断阈值,在矩阵乘法的函数中被使用
构造函数中 = 15 也就是Mikolov在论文中提到的
|\mathbf{e}| \in (-15, 15)
*/
real gradient_cutoff;
/* dynamic > 0: 边测试边学习
构造函数中 dynamic = 0 不选择动态测试学习
*/
real dynamic;
/* 学习率 构造函数中 = 0.1 */
real alpha;
/* 训练初始的学习率 */
real starting_alpha;
/* alpha_divid == 0: 不将alpha减半
构造函数中 = 0
*/
int alpha_divide;
/* 累计对数概率
logp = \sum_{i} log10(w_i)
构造函数中 = 0
llogp 指 last logp
构造函数中 = -100000000 负无穷大
*/
double logp, llogp;
/* 最小增长倍数
构造函数中 = 1.003
*/
float min_improvement;
/* 训练集的训练次数 构造函数中 = 0 */
int iter;
/* 词汇集的最大容量,并且在代码中动态增加
构造函数中 = 100
*/
int vocab_max_size;
/* 词汇集的实际大小
构造函数中 = 0
*/
int vocab_size;
/* 训练集中的词汇量
构造函数中 = 0
*/
int train_words;
/* 当前词在训练集中的位置,是第几个词
构造函数中 = 0
*/
int train_cur_pos;
int counter;
/* one_iter == 1 只训练一遍
构造函数中 = 0 不选用
*/
int one_iter;
/* 训练集的最大训练次数
构造函数中 = 0
*/
int maxIter;
/* 每次训练的单词数,会被保存到rnnlm_file */
int anti_k;
/* L2正则化系数 */
real beta;
/* 单词分类的种类
构造函数中 = 100
*/
int class_size;
/* 二维指针class_words[i-1][j-1]指第i类的第j个词
在词汇集vocab中的下标
*/
int **class_words;
/* 词汇类计数,在第i类中有class_cn[i-1]个单词 */
int *class_cn;
/* 第i类中最多有class_max_cn[i-1]个单词 */
int *class_max_cn;
/* 选择分类词的算法
构造函数中 = 0
*/
int old_classes;
/* 不重复的词汇集,数据类型见前 */
struct vocab_word *vocab;
/* 根据词频vocab.cn对vocab[1: vocab_size-1]选择排序 */
void sortVocab();
/* 存放word在词汇集vocab中的下标,下标由hash函数映射得到
构造函数中:
vocab_hash_size=100000000; hash数值小于100000000
vocab_hash=(int *)calloc(vocab_hash_size,
*/
int *vocab_hash;
int vocab_hash_size;
/* 输入层 */
int layer0_size;
/* 隐藏层
构造函数中 = 30
*/
int layer1_size;
/* 压缩层 */
int layerc_size;
/* 输出层 */
int layer2_size;
/* ME模型中输入层到输出层的直连
构造函数中 = 0
*/
long long direct_size;
/* ME模型采用的特征阶数
构造函数中 = 0
*/
int direct_order;
/* history存放单词:
history[0]存放w_t,history[1]存放w_{t-1},类推
*/
int history[MAX_NGRAM_ORDER];
/* bptt <= 0="" 1="" 为常规的bptt,从s_{t}展开到s_{t-1}="" 构造函数中="0,为常规的bptt" *="" int="" bptt;="" 每次训练bptt_block个单词,使用bptt="" bptt_block;="" 也存放单词,下标从0开始存放w_{t},="" w_{t-1}="" 空指针="" *bptt_history;="" 存放隐藏层的状态,下标从0开始存放s_{t},="" s_{t-1}="" neuron="" *bptt_hidden;="" 输入层到隐藏层的权值,bptt中使用="" struct="" synapse="" *bptt_syn0;="" gen;="" 句子的独立训练="" independent="" !="0" 要求每个句子独立训练="" 上一个句子对下一个句子的训练算历史信息="" independent;="" 下列一系列指针在构造函数中="NULL" neurons="" in="" input="" layer="" *neu0;="" hidden *neu1;="" *neuc;="" output="" *neu2;="" weights="" between="" and="" *syn0;="" (or="" compression="" if="">0)
*/
struct synapse *syn1;
/* weights between hidden and compression layer */
struct synapse *sync;
/* direct parameters between input and
output layer (similar to Maximum Entropy model
parameters)
*/
direct_t *syn_d;
//backup used in training:
/* 数据备份 */
struct neuron *neu0b;
struct neuron *neu1b;
struct neuron *neucb;
struct neuron *neu2b;
struct synapse *syn0b;
struct synapse *syn1b;
struct synapse *syncb;
direct_t *syn_db;
//backup used in n-bset rescoring:
struct neuron *neu1b2;
以上是CRnnLM的成员变量以及构造函数中的赋值情况。
rnnlmlib.cpp
CRnnLM除了成员变量以外,还有成员函数。Mikolov在组织文件时,自然所有的函数声明在类CRnnLM内,然后除了构造函数和析构函数以外,其他成员函数在rnnlmlib.cpp中实现。
/* 返回一个大小在 min 到 max 之间的 real 类型的浮点数 */
real CRnnLM::random(real min, real max)
{
return rand()/(real)RAND_MAX*(max-min)+min;
}
/* 设置训练集的文件名 */
void CRnnLM::setTrainFile(char *str)
{
strcpy(train_file, str);
}
/* 设置验证集、测试集、模型储存的文件名,代码基本相同 */
void CRnnLM::setValidFile(char *str);
void CRnnLM::setTestFile(char *str);
void CRnnLM::setRnnLMFile(char *str);
/* 中间若干 void set 函数都是通过 public 的成员函数
来修改 protected 的成员变量,故此略去
*/
词汇集 vocab 的操作。其中几个hash方面的函数主要是为最大熵模型 - Maximum Entropy 服务的。
/* 从文件 fin 中读取格式化单词到 word */
void CRnnLM::readWord(char *word, FILE *fin);
/* 返回单词的hash值 */
int CRnnLM::getWordHash(char *word);
/* 在词汇集中搜索word的索引 */
int CRnnLM::searchVocab(char *word);
/* 给出当前文件指针所指的单词在vocab中的索引 */
int CRnnLM::readWordIndex(FILE *fin);
/* 将形参加入vocab */
int CRnnLM::addWordToVocab(char *word);
/* vocab的选择排序 */
void CRnnLM::sortVocab();
/* 从训练集中读取词汇到vocab词汇集 */
void CRnnLM::learnVocabFromTrainFile()
/***************************************/
/* 从文件 fin 中读取格式化单词到 word */
void CRnnLM::readWord(char *word, FILE *fin)
{
int a=0, ch;
while (!feof(fin)) { // 遍历文件 fin 中的字符
ch=fgetc(fin);
if (ch==13) continue;
/* 遇到回车键时本应结束,但仍然继续读文件 */
/* 如果遇到了单词的分隔符 */
if ((ch==' ') || (ch=='\t') || (ch=='\n')) {
if (a > 0) {
if (ch=='\n') ungetc(ch, fin);
/* 把字符 ch 退回到输入流 fin */
break;
}
if (ch=='\n') {
strcpy(word, (char *)" < /s > ");
return;
}
else continue;
}
word[a]=ch; // 将输入流中读到的字符复制到word
a++;
if (a > =MAX_STRING) { // 字符串长度溢出
//printf("Too long word found!\n");
//truncate too long words
a--;
}
}
word[a]=0; // 用0作为字符串的截止符
}
/***************************************/
/* 返回单词的hash值 */
int CRnnLM::getWordHash(char *word)
{
unsigned int hash, a;
hash=0;
/* 根据字符串每个字符的ASCII进行计算 */
for (a=0; a < strlen(word); a++) hash=hash*237+word[a];
hash=hash%vocab_hash_size;
return hash;
}
/***************************************/
/* 在词汇集中搜索word的索引 */
int CRnnLM::searchVocab(char *word)
{
int a;
unsigned int hash;
hash=getWordHash(word); // 计算hash
if (vocab_hash[hash]==-1) return -1;
/* 在hash之后的词汇集中根据hash值查询对应的单词 */
if (!strcmp(word, vocab[vocab_hash[hash]].word)) return vocab_hash[hash];
for (a=0; a < vocab_size; a++) { //search in vocabulary
if (!strcmp(word, vocab[a].word)) {
vocab_hash[hash]=a;
return a;
}
}
return -1; //return OOV if not found
}
/***************************************/
/* 给出当前文件指针所指的单词在vocab中的索引 */
int CRnnLM::readWordIndex(FILE *fin)
{
char word[MAX_STRING];
readWord(word, fin) // 读取当前文件指针所指的单词
if (feof(fin)) return -1;
return searchVocab(word) // 返回该单词在词汇集中的索引
}
/***************************************/
/* 将形参加入vocab */
int CRnnLM::addWordToVocab(char *word)
{
unsigned int hash;
strcpy(vocab[vocab_size].word, word);
vocab[vocab_size].cn=0;
vocab_size++; // 像队列一样,vocab增长一个词汇
/* vocab增长到max_size满了,再分配更多的空间 */
if (vocab_size+2 > =vocab_max_size) {
//reallocate memory if needed
vocab_max_size+=100;
vocab=(struct vocab_word *)realloc(vocab, vocab_max_size * sizeof(struct vocab_word));
}
/* 同时把word加入散列表中 */
hash=getWordHash(word);
vocab_hash[hash]=vocab_size-1;
return vocab_size-1;
}
/***************************************/
/* vocab的选择排序 */
void CRnnLM::sortVocab()
{
int a, b, max;
vocab_word swap;
for (a=1; a < vocab_size; a++) {
max=a;
/* 根据频数进行选择排序 */
for (b=a+1; b < vocab_size; b++) if (vocab[max].cn < vocab[b].cn) max=b;
swap=vocab[max];
vocab[max]=vocab[a];
vocab[a]=swap;
}
}
/***************************************/
/* 从训练集中读取词汇到vocab词汇集 */
void CRnnLM::learnVocabFromTrainFile()
//assumes that vocabulary is empty
{
char word[MAX_STRING];
FILE *fin;
int a, i, train_wcn;
/* 先将hash词汇集填满-1
以免无法填满散列表,并且标识空散列的位置
*/
for (a=0; a < vocab_hash_size; a++) vocab_hash[a]=-1;
fin=fopen(train_file, "rb");
/* 刚初始化的词汇表为空 */
vocab_size=0;
addWordToVocab((char *)" < /s > ");
train_wcn=0; // 训练集中的单词数量
/* 将文件指针遍历文件
不断将训练集中的单词添加到词汇集vocab
*/
while (1) {
readWord(word, fin);
if (feof(fin)) break;
train_wcn++;
/* 根据单词频数选择排序 */
i=searchVocab(word);
if (i==-1) { // 如果word没有在词汇集中出现过
a=addWordToVocab(word);
vocab[a].cn=1;
} else vocab[i].cn++; // 如果出现过
}
sortVocab(); // 根据单词的频数进行选择排序
if (debug_mode > 0) {
printf("Vocab size: %d\n", vocab_size);
printf("Words in train file: %d\n", train_wcn);
}
train_words=train_wcn;
fclose(fin);
}
保存与恢复的函数,neu和syn系列的成员变量与neub和synb系列的备份变量相互赋值
void CRnnLM::saveWeights(); //saves current weights and unit activations void CRnnLM::restoreWeights(); //restores current weights and unit activations from backup copy void CRnnLM::saveContext(); //useful for n-best list processing void CRnnLM::saveContext2(); void CRnnLM::restoreContext2();
初始化设定,相似的代码都略过
/* 网络初始化 */
void CRnnLM::initNet()
{
int a, b, cl;
layer0_size=vocab_size+layer1_size;
layer2_size=vocab_size+class_size;
/* 为输入层、隐藏层、压缩层、输出层分配空间 */
neu0=(struct neuron *)calloc(layer0_size, sizeof(struct neuron));
/* 为相应的突触分配空间 */
syn0=(struct synapse *)calloc(layer0_size*layer1_size, sizeof(struct synapse));
/* 为输入层、隐藏层、压缩层、输出层的备份神经元分配空间 */
neu0b=(struct neuron *)calloc(layer0_size, sizeof(struct neuron));
/* 为相应的突触备份分配空间 */
syn0b=(struct synapse *)calloc(layer0_size*layer1_size, sizeof(struct synapse));
/* 将输入层、隐藏层、压缩层、输出层所有的神经元的实值、误差值赋值为零 */
for (a=0; a < layer0_size; a++) {
neu0[a].ac=0;
neu0[a].er=0;
}
/* 为相应的突触赋值 */
for (b=0; b < layer1_size; b++) for (a=0; a < layer0_size; a++) {
syn0[a+b*layer0_size].weight=random(-0.1, 0.1)+random(-0.1, 0.1)+random(-0.1, 0.1);
}
/* ME模型中直连的突触赋值 */
long long aa;
for (aa=0; aa < direct_size; aa++) syn_d[aa]=0;
/* 选择bptt方式训练 */
if (bptt > 0) {
bptt_history=(int *)calloc((bptt+bptt_block+10), sizeof(int));
for (a=0; a < bptt+bptt_block; a++) bptt_history[a]=-1;
//
bptt_hidden=(neuron *)calloc((bptt+bptt_block+1)*layer1_size, sizeof(neuron));
for (a=0; a < (bptt+bptt_block)*layer1_size; a++) {
bptt_hidden[a].ac=0;
bptt_hidden[a].er=0;
}
//
bptt_syn0=(struct synapse *)calloc(layer0_size*layer1_size, sizeof(struct synapse));
if (bptt_syn0==NULL) {
printf("Memory allocation failed\n");
exit(1);
}
}
saveWeights(); // 将权值备份储存
下面一段仍然是初始化函数 - initNet() 的一部分,是有关分类优化的处理,所以特别提出来展示。Mikolov提到,这部分运算是在训练之前实现的,所以相关的代码出现在initNet()内:
/* 输出层分解 - Factorization of the output layer
frequency binning
*/
double df, dd;
int i;
df=0; // 遍历到当前word的频率加总
dd=0;
a=0; // 分类的class序数,从0开始生长
b=0; // vocab中单词频数加总
if (old_classes) { // 选择一种词的分类算法
/* b 加总vocab词汇集中所有单词的频数 */
for (i=0; i < vocab_size; i++) b+=vocab[i].cn;
for (i=0; i < vocab_size; i++) {
/* 加总频率 */
df+=vocab[i].cn/(double)b;
/* 保证频率之和必定==1,规避一些计算错误 */
if (df > 1) df=1;
/* 根据遍历到当前的word频率加总与代表当前class
的a比较。也就是说直到df累加到超过a所占的比率,
class前进一位
*/
if (df > (a+1)/(double)class_size) {
vocab[i].class_index=a;
if (a < class_size-1) a++;
} else {
vocab[i].class_index=a;
}
}
} else { /* 另一种算法 */ }
//allocate auxiliary class variables
//(for faster search when normalizing probability
//at output layer)
class_words=(int **)calloc(class_size, sizeof(int *));
class_cn=(int *)calloc(class_size, sizeof(int));
class_max_cn=(int *)calloc(class_size, sizeof(int));
for (i=0; i < class_size; i++) {
class_cn[i]=0;
class_max_cn[i]=10;
/* 二维数组int **class_words;进一步分配空间 */
class_words[i]=(int *)calloc(class_max_cn[i], sizeof(int));
}
/* 按照class_words[cl][class_cn[cl]]来赋值,skip */
}
下面是神经网络对文件的输入输出方面的函数,也不必深究。
/* 将网络模型的所有信息fprintf打印储存到rnnlm_file文件中 虽然这个函数本身的对网络训练没什么助益,但是可以通过 fprintf打印的内容与格式来理解不同变量在程序中的意义, 对理解程序帮助较大。 */ void saveNet(); /* 在文件中找到ASCII == delim的字符,使文件指针fi指向 这个字符 - delim 出现的下一个字符位置 这个函数是为了下一个加载信息 restoreNet()服务的 */ void goToDelimiter(int delim, FILE *fi); /* 从rnnlm_file文件中读取所有的网络信息,通过goToDelimiter() 进行定位,将从文件中读取到的网络信息加载到成员变量的 指针地址上,从而根据rnnlm_file恢复网络 */ void restoreNet(); /* 清除所有的激活值和误差向量,将神经元的ac, er置零 */ void netFlush(); /* 将隐藏层的ac值置一 neu1[].ac = 1, bptt+history置零 */ void netReset();
接下来是正儿八经的网络训练部分的函数了。需要注意的是,这个神经网络的训练是有class层的,可以参看论文部分的博文,当然更好的是直接看Mikolov的博士论文,更更好的是顺带读一读列出的参考论文。但是需要注意的是代码中的网络结构并非与论文中描述的一模一样,具体可以看下面这张图:
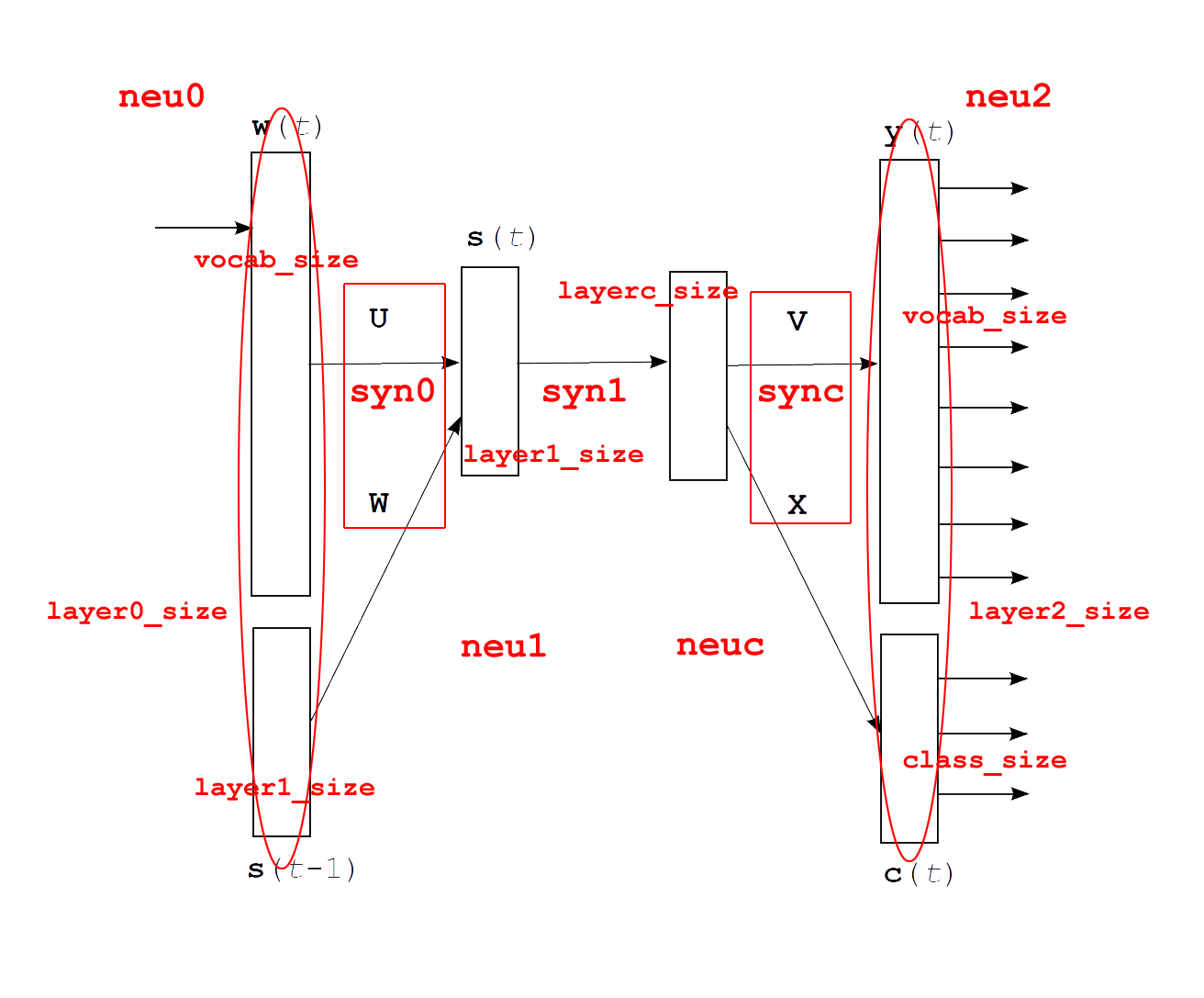
在训练过程中并没有采用两个单独的矩阵( \mathbf{U}, \mathbf{W} ) 而是只用了一个 syn0. 同时,也没有分为 ( \mathbf{w}(t), \mathbf{s}(t-1) ) 进行输入,而是将它们并括为neu0.
/* 突触矩阵与神经元向量乘积的函数 主要用于下面传播过程中的各种计算 */ void CRnnLM::matrixXvector(struct neuron *dest, struct neuron *srcvec, struct synapse *srcmatrix, int matrix_width, int from, int to, int from2, int to2, int type);
前向传播过程
void CRnnLM::computeNet(int last_word, int word)
{ /* 形参相当于论文中的 w_{t-1}, w_{t} */
int a, b, c;
real val;
/* sum is used for normalization: it's better
to have larger precision as many numbers
are summed together here
*/
double sum;
/* 如果上一个单词不是终止符
将neu0激活成在last_word位置one-hot 的词向量
*/
if (last_word!=-1) neu0[last_word].ac=1;
/******************************************/
/* START 从输入层传播到隐藏层 */
/* 将所有隐藏层的神经元ac值置零 */
for (a=0; a < layer1_size; a++) neu1[a].ac=0;
/* 将所有class层神经元的ac值置零 */
for (a=0; a < layerc_size; a++) neuc[a].ac=0;
/* 进行矩阵运算,注意看这里:实际上matrixXvector()
函数并没有直接计算 neu1 = syn0 * neu0,而是计算
[from : to]的部分,也就是说实际上这里的调用计算的
是:
neu0[0size - 1size : 0size]
* syn0[0 : 1size][0size - 1size : 0size]
也就是说输入层计算的神经元实际上是最后layer1_size个,
也就是 s(t-1) 的部分
*/
matrixXvector(neu1, neu0, syn0, layer0_size, 0,
layer1_size, layer0_size-layer1_size, layer0_size,
0);
/* 再将neu0中 onehot 词向量部分的矩阵运算加上去 */
for (b=0; b < layer1_size; b++) {
a=last_word;
if (a!=-1) neu1[b].ac += neu0[a].ac * syn0[a+b*layer0_size].weight;
}
/* 通过 sigmoid 激活到隐藏层 */
for (a=0; a < layer1_size; a++) {
/* 为了数据稳定性,将ac值限定在[-50, 50]以内 */
if (neu1[a].ac > 50) neu1[a].ac=50;
if (neu1[a].ac < -50) neu1[a].ac=-50;
val=-neu1[a].ac;
neu1[a].ac=1/(1+fasterexp(val));
}
/* END 从输入层传播到隐藏层 */
/******************************************/
/* */
/******************************************/
/* START 从隐藏层传播到压缩层 */
if (layerc_size > 0) { /* 计算压缩层 */
/* 计算 neuc = neu1[0 : 1size]
* syn1[0 : csize][0 : 1size]
*/
matrixXvector(neuc, neu1, syn1, layer1_size,
0, layerc_size, 0, layer1_size, 0);
/* sigmoid与数值稳定性 */
for (a=0; a < layerc_size; a++) {
if (neuc[a].ac > 50) neuc[a].ac=50;
if (neuc[a].ac < -50) neuc[a].ac=-50;
val=-neuc[a].ac;
neuc[a].ac=1/(1+fasterexp(val));
}
}
/* END 从隐藏层传播到压缩层 */
/******************************************/
/* */
/******************************************/
/* START 从隐藏层传播到输出层 - class */
for (b=vocab_size; b < layer2_size; b++) neu2[b].ac=0;
if (layerc_size > 0) { /* 中间经过压缩层 */
matrixXvector(neu2, neuc, sync, layerc_size,
vocab_size, layer2_size, 0, layerc_size, 0);
}
else /* 不计算压缩层,直接从隐藏层计算到输出层 */
{
matrixXvector(neu2, neu1, syn1, layer1_size,
vocab_size, layer2_size, 0, layer1_size, 0);
}
/* 最大熵模型 - Maxmium Entropy Model
对neu2的class部分采用直连的方法
*/
if (direct_size > 0) { /* 使用ME模型 */
unsigned long long hash[MAX_NGRAM_ORDER];
//this will hold pointers to syn_d that contains hash parameters
for (a=0; a < direct_order; a++) hash[a]=0;
for (a=0; a < direct_order; a++) {
b=0;
if (a > 0) if (history[a-1]==-1) break;
/* if OOV was in history, do not use this N-gram
feature and higher orders
*/
hash[a]=PRIMES[0]*PRIMES[1];
for (b=1; b < =a; b++)
hash[a]+=
PRIMES[(a*PRIMES[b]+b)%PRIMES_SIZE]
*(unsigned long long)(history[b-1]+1);
/* update hash value based on words from the history */
hash[a]=hash[a]%(direct_size/2);
/* make sure that starting hash index is in the first
half of syn_d (second part is reserved for
history- > words features)
*/
}
for (a=vocab_size; a < layer2_size; a++) {
for (b=0; b < direct_order; b++) if (hash[b]) {
neu2[a].ac+=syn_d[hash[b]];
//apply current parameter and move to the next one
hash[b]++;
} else break;
}
}
/* softmax的计算
这里的softmax计算采用了一个小技巧,以防在计算exp时
指数爆炸,就是softmax分子分母同时除以e^{maxAc}:
\frac{e^{ac}}{\sum_{i} e^{ac_{i}}}
= \frac{e^{ac - maxAc}}{\sum_{i} e^{ac_{i} - maxAc}}
*/
sum=0;
real maxAc=-FLT_MAX;
for (a=vocab_size; a < layer2_size; a++)
if (neu2[a].ac > maxAc) maxAc=neu2[a].ac;
//this prevents the need to check for overflow
for (a=vocab_size; a < layer2_size; a++)
sum+=fasterexp(neu2[a].ac-maxAc);
for (a=vocab_size; a < layer2_size; a++)
neu2[a].ac=fasterexp(neu2[a].ac-maxAc)/sum;
if (gen > 0) return;
/* if we generate words, we don't know what current
word is - > only classes are estimated and word
is selected in testGen()
*/
/* END 从隐藏层传播到输出层 - class */
/******************************************/
/* */
/******************************************/
/* START 从隐藏层传播到输出层 - word */
if (word!=-1) {
/* word所在的class的所有词的ac值被置零 */
for (c=0; c < class_cn[vocab[word].class_index]; c++){
neu2[class_words[vocab[word].class_index][c]].ac=0;
}
if (layerc_size > 0) {
/* 计算word所在class的词从压缩层传播到输出层 */
matrixXvector(neu2, neuc, sync, layerc_size,
class_words[vocab[word].class_index][0],
class_words[
vocab[word].class_index][0]
+class_cn[vocab[word].class_index],
0, layerc_size,
0);
}
else /* 否则word所在class内的词直接从隐藏层传播到输出层 */
{
matrixXvector(neu2, neu1, syn1, layer1_size,
class_words[vocab[word].class_index][0],
class_words[
vocab[word].class_index][0]
+class_cn[vocab[word].class_index],
0, layer1_size,
0);
}
}
/* 最大熵模型 - Maxmium Entropy Model
对neu2的word部分采用直连的方法
skip
*/
/* softmax skip */
/* END 从隐藏层传播到输出层 - word */
/******************************************/
/* */
}
反向传播过程
void CRnnLM::learnNet(int last_word, int word)
未完