Sutskever RNN文本生成
这篇博客基于Hinton的弟子Sutskever在2011年的ICML论文Generating Text with Recurrent Neural Networks。这篇文章同时也被收录为Sutskever的博士论文Training Recurrent Neural Networks的第五章主要内容。
这篇文章提出了Tensor RNN模型,及由此改进的Multiplicative RNN模型。
Tensor RNN
之所以提出这两个模型,是因为传统的RNN在字符级别(character-level)的语言模型上的表现并不出众,而Sutskever等人改进的MRNN的表现得却更好。关于标准RNN模型在字符级别上的表现,Sutskever是这样解释的:
$$ ht = \tanh \left( \mathbf{W}{hv} \cdot \mathbf{v}t + \mathbf{W}{hh} \cdot \mathbf{h}_{t-1} + \mathbf{b}_h \right ) $$
$$ \mathbf{o}t = \mathbf{W}{oh} \cdot \mathbf{h}_t + \mathbf{b}_o $$
首先,输入的字符向量 $ \mathbf{v}_t $ 首先需要经过visible-to-hidden与 $ \mathbf{v}t $ 无关的矩阵 $\mathbf{W}{hv}$ 线性变换,然后再加到当前的隐态(输入当前隐态输入的计算就与输入向量无关了)上,才到达隐藏层。按照Sutskever的看法,这样的传播过程对于当前输入而言显得有些曲折,特别是在 $ \mathbf{W}{hh} \cdot \mathbf{h}{t-1} $ 这里,削弱了输入对隐藏层的影响。所以,Sutskever希望输入对隐藏层的影响能够更加直接,因此他改造了输入向量经过的线性变换矩阵:
$$ ht = \tanh \left( \mathbf{W}{hv} \cdot \mathbf{v}t + \color{red}{\mathbf{W}{hh}^{(\mathbf{v}t)}} \cdot \mathbf{h}{t-1} + \mathbf{b}_h \right ) $$
$$ \mathbf{o}t = \mathbf{W}{oh} \cdot \mathbf{h}_t + \mathbf{b}_o $$
也就是说,矩阵 $\mathbf{W}_{hv}$ 也要被输入向量 $ \mathbf{v}_t $ 决定。实际上,这里的网络结构变化相当于产生了这样一个二元函数:
$$ \mathbf{W}_{hh}^{(\mathbf{v}t)} \cdot \mathbf{h}{t-1} = \psi ( \mathbf{v}t, \mathbf{h}{t-1} ) $$
二元函数 $\psi ( \mathbf{v}t, \mathbf{h}{t-1} )$ 直接从输入向量与先前隐态决定了传播到隐藏层的内容,这样设定实际上是有具体的语义解释的。在论文中Sutskever举出了一个例子,譬如对于fixing, breaking这两个动词变化,在出现序列fixi, breaki的时候,一个好的语言模型应该能预测出下一个字符是n。
我在这里用函数 $\theta(\bullet), \mu(\bullet), H(\bullet)$ 抽象一下,直接表示输入输出过程。传统的RNN模型对于这个例子的处理是这样的:
$$ h_t = \tanh \left( \theta (“i”) + \mu (H(“break”)) + \mathbf{b}_h \right ) $$
而改进的模型是这样处理的:
$$ h_t = \tanh \left( \theta (“i”) + \psi (H(“break”), “i”) + \mathbf{b}_h \right ) $$
可以看到,第二项先前隐态 $H(“break”)$ 也和当前输入 $”i”$ 联系起来,从而传播到隐藏层时当前输入的 $”i”$ 的影响更大,进而更容易预测 $”n”$.
对于这一结构有更深层的解释。Sutskever在论文中提到,从某种意义上讲,这样的处理是将RNN看做无界树(unbounded tree). 其中,unbounded tree的每一个结点表示一个隐态向量,每一条边是代表从父结点移动到子结点的字符,也就是说以上的例子有这样的过程:
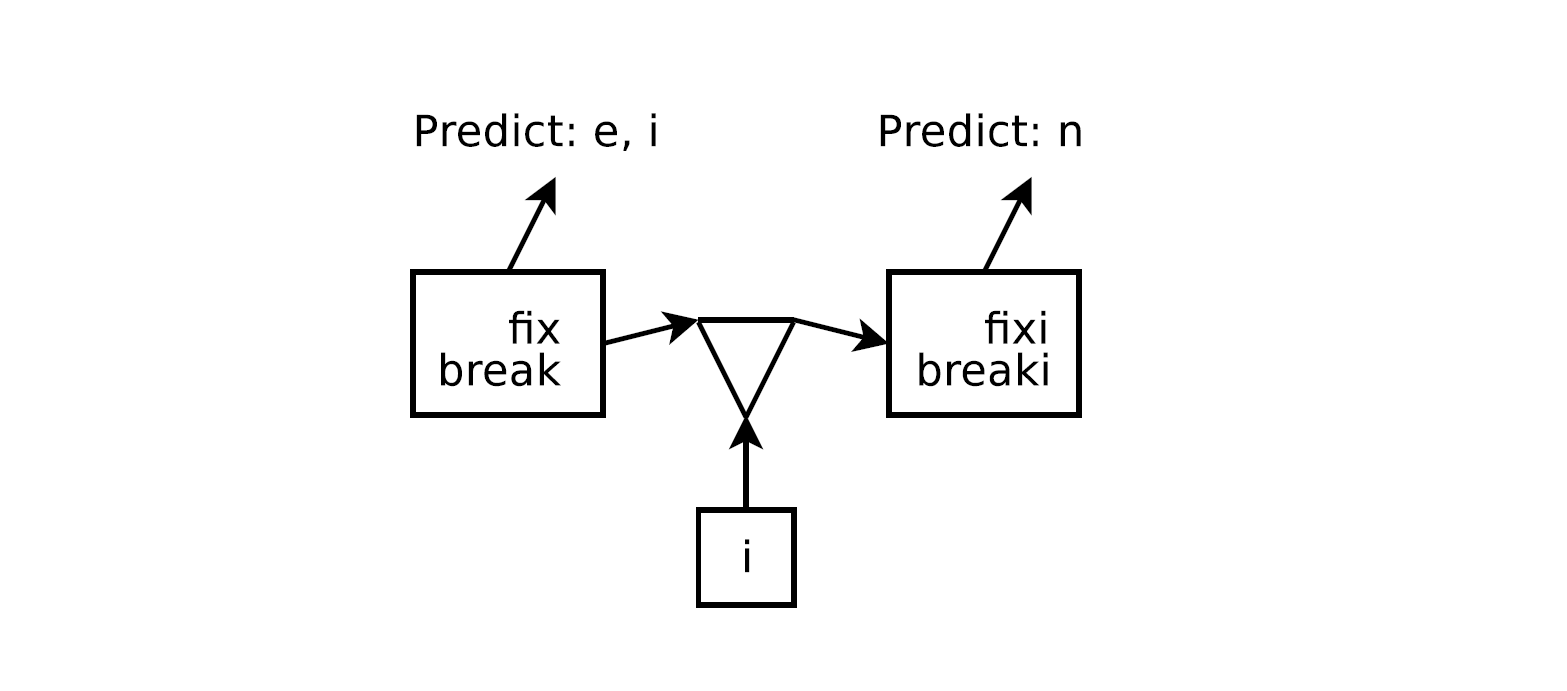
根据Sutskever的说法,这实际上强调了RNN与Markov模型的相似性。但是比起Markov模型更为优越的是,RNN能够共享参数!也就是说,RNN能够很容易地将储存着break和fix的信息的两个隐态向量都识别为动词词干(verb-stem).但是对于普通的Markov模型而言,这是做不到的。
而且,从之前二元函数 $\psi ( \mathbf{v}t, \mathbf{h}{t-1} )$ 来看,将隐藏向量识别为动词,和当前输入$”i”$,这两个要素共同决定了下一个预测是$”n”$。所以RNN对于隐态的处理对于这个模型是非常重要的,因为它决定了两个要素之一,而另一个要素则被改造为直接参与到矩阵 $\mathbf{W}_{hh}^{(\mathbf{v}_t)}$ 中。
总而言之,张量RNN让每一个字符确定了一个不同的隐藏层到隐藏层的矩阵。输入的字符向量如果使用1-of-M的one-hot方式进行储存,那么总共能有M种不同的字符,也对应了M个不同的矩阵 $\mathbf{W}{hh}^{(1)}, \ldots, \mathbf{W}{hh}^{(M)}$,将这些矩阵排在一起也就变成了张量(tensor)。而对于1-of-M表达的向量而言,做内积运算就相当于选出一个矩阵,所以可以定义:
$$ \mathbf{W}_{hh}^{(\mathbf{v}t)} = \sum{m=1}^{M} \mathbf{v}t^{(m)} \cdot \mathbf{W}{hh}^{(m)} $$
其中 $\mathbf{v}_t^{(m)}$ 是向量 $\mathbf{v}_t$ 的第m个分量。
Multiplicative RNN
Tensor表达有一个显而易见的问题,就是储存困难。在隐藏层单元很多,字符向量维度很高的情况下,张量的储存要求就非常高。所以Sutskever等人希望通过分解张量来减少储存:
$$ \mathbf{W}_{hh}^{(\mathbf{v}t)} \equiv \mathbf{W}{hf} \cdot \mathbf{diag}(\mathbf{W}{fv} \cdot \mathbf{v}{t}) \cdot \mathbf{W}_{fh} $$
当 $ dim(\mathbf{W}{fv} \cdot \mathbf{v}{t}) $ 足够大时,张量分解之后的表达能力和分解之前几乎相当,但是储存代价高;反之,如果维度不是很高,也能保留原先张量的大部分表达能力。可以看到,这样的分解实际上也和先前所提的二元函数 $\psi ( \mathbf{v}t, \mathbf{h}{t-1} )$的表达有相似之处,表现在网络模型上就是中间那层三角形:
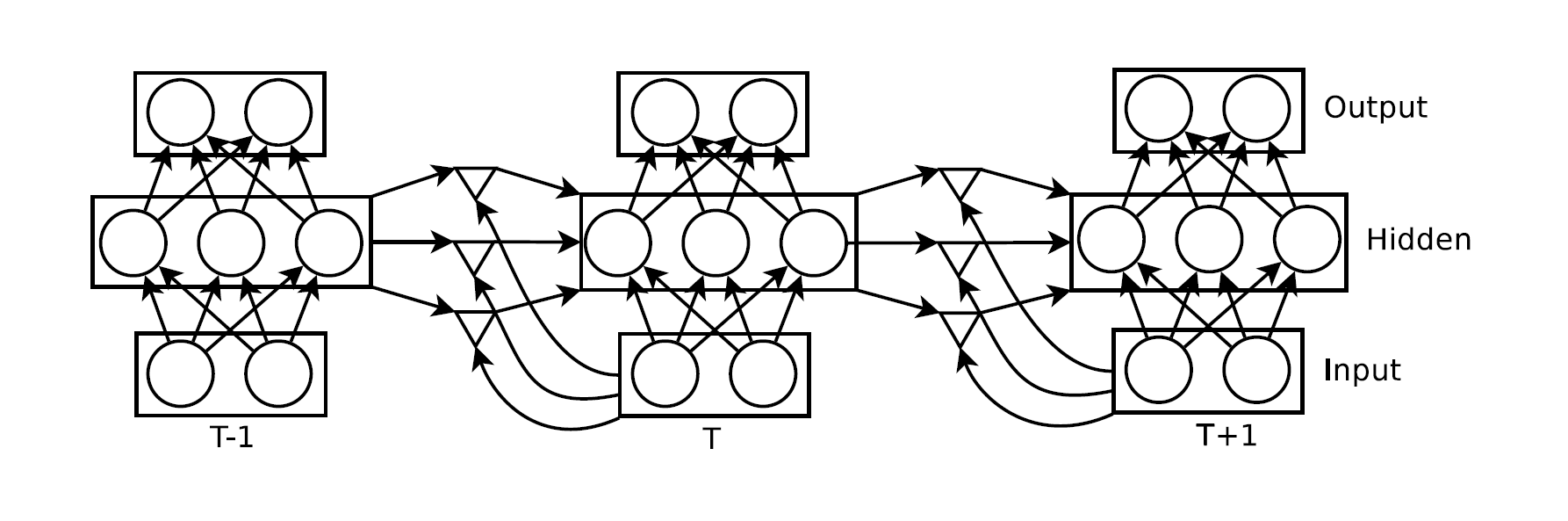
三角形层,也就是分解层,其中的三角形左边顶点输入隐藏层的状态,比如在之前的例子中隐藏层表达出来的语义就是动词;下面顶点输入当前字符,也就是$”i”$,这两个顶点分别代表 $\mathbf{W}{fh} \cdot \mathbf{h}{t-1}$ 和 $\mathbf{diag}(\mathbf{W}_{fv})$:
$$ \color{red}{\mathbf{f}t = \mathbf{diag}(\mathbf{W}{fv} \cdot \mathbf{v}{t}) \cdot (\mathbf{W}{fh} \cdot \mathbf{h}_{t-1})} $$
$$ \mathbf{h}t = \tanh ( \mathbf{W}{hf} \cdot \color{red}{\mathbf{f}t} + \mathbf{W}{hv} \cdot \mathbf{v}_{t} ) $$
$$ \mathbf{o}t = \mathbf{W}{oh} \cdot \mathbf{h}_t + \mathbf{b}_o $$
因此,实际上MRNN每次输入时,实际上在隐藏层中有两步非线性处理。
对于目标函数,依然采用softmax: $P(\mathbf{v}{t+1}|\mathbf{v}{\leq t}) = softmax ( \mathbf{o}_t)$