UCB Summary
这篇博客基于UCB的自然语言组在2016年ACL会议上面发表的论文Learning-Based Single-Document Summarization with Compression and Anaphoricity Constraints, 是一篇关于用SVM方法训练模型参数,采用单文件而非多文件的摘要模型。
模型 - Model
不需要什么铺垫了,直接上模型吧:
$$ \max{ \color{green}{\mathbf{x}^{UNIT}}, \color{blue}{\mathbf{x}^{REF}} } \left[ \color{green}{\sum{i} \left[ x_i^{UNIT} (\mathbf{w}^T \mathbf{f}(ui)) \right] } + \color{blue}{ \sum{(i, j)} \left[ x{ij}^{REF} (\mathbf{w}^T \mathbf{f}(r{ij})) \right] } \right] $$
这个模型被分成了两个部分,绿色的部分是抽取文章重要信息的得分 - Extraction Score,蓝色的部分是评价代词呼应关系的得分 - Anaphora Score。这些评分是根据从训练集中习得的特征函数 ( \mathbf{f}(\bullet) ) 和权重参数 (\mathbf{w}^T) 来计算的,同时抽取过程中必须要满足模型对长度的限制:
$$ \sum_{i} x_i^{UNIT} |ui| + \sum{(i, j)} x{ij}^{REF}(|r{ij}|-1) \le k $$
类似的限制有语法性、长度、代词对应的限制,目的就是为了得到合理的摘要。
另外,模型中(\mathbf{w}^T)就是SVM方法所要训练的对象,基于New York Times新闻报道的标记语料库。关于基于单文件的摘要是怎样实现的,上面模型式的具体含义是什么,模型的评价方法,都在下文一一展开:
语法性限制 - Grammaticality Constraints
修辞结构理论 - Rhetorical Structure Theory
首先,句子有不同程度的,或者说不同方式的 - 分解,或者说压缩。比如下面这样在论文中出现的图:
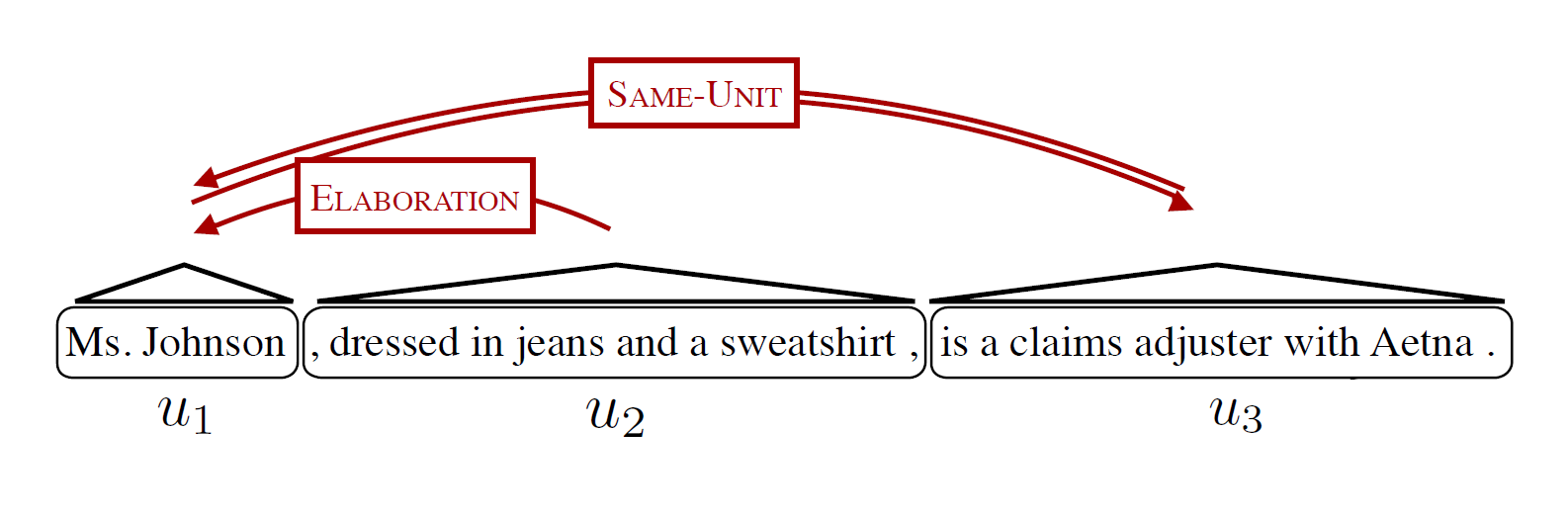
这样的压缩是基于修饰关系(RST - Rhetorical Structure Theory)而产生的。暂不论RST,而可以借此理解模型中的一些定义。在这里,这句话/文本被分割为三个文本单元(textual units),于是构成了一个文本单元集:
$$ \mathbf{u} = (u_1, u_2, u_3) $$
严谨地讲,这些文本单元是模型抽取信息时的基本单元,其形式是句子中的连续部分。显然,这些units之间的依存关系实际上体现了语法性的限制。比如说上面这个例子,从RST修辞的角度来看,句子被分割为相互之间有修饰关系的基础话语单元(EDU - Elementary discourse unit)。可以看到:( u_2 ) = “dressed in jeans and a sweatshirt”是一个插入语,修饰了(u_1) = “Ms.Johnson”,而( u_3 )实际上和(u_1)是同一句话,相互之间并列而没有修饰关系,所以被标记为SAME-UNIT。
如果将EDU的关系整理成一棵树,就像上图展示的一样,(u_2) 应该成为(u_1,u_3)的子结点,而(u_1,u_3)在修饰逻辑上应属于同一个结点。这样,在我们做摘要对文本中的成分进行删除时,就应该考虑到SAME-UNIT的结点,比如(u_1,u_3),应该悲欢同生死共,而父节点没有删除时,子结点(u_2)是可以删除的。从树的角度看,或者直接从修辞逻辑看,(u_2)依存于(u_1),而(u_1)和(u_3)相互依存。这个关系在模型中形式化表达为:
$$ \forall i, k \: x_i^{UNIT} \leq x_k^{UNIT} $$
若 (u_i) 依存于 (u_k)
到这里我们需要澄清集合(\mathbf{x}^{UNIT} = (x_1^{UNIT}, \ldots, x_n^{UNIT}))的概念了。这个集合的元素是数字指标,用以量化指示文本单元之间的关系。比如上式中的数值比较,实际上就反应了RST下EDU的修辞关系,或者说包含的层次,EDU在句子之中的重要地位 - 例如作为修饰语的 (u_2) 的重要性比较低、包含层次比较靠近底层的子集,所以占有的 (x_2^{UNIT})小于它的父节点。这样在模型训练时,优化(\mathbf{x}^{UNIT})集合,也就顺理成章地提取了最重要的文本信息,当然这个信息是经过特征与权重调整之后的。
句法与联合压缩 - Syntactic and Combined compressions
联合压缩是结合了RST与句法的压缩。先简单看一下句法压缩:
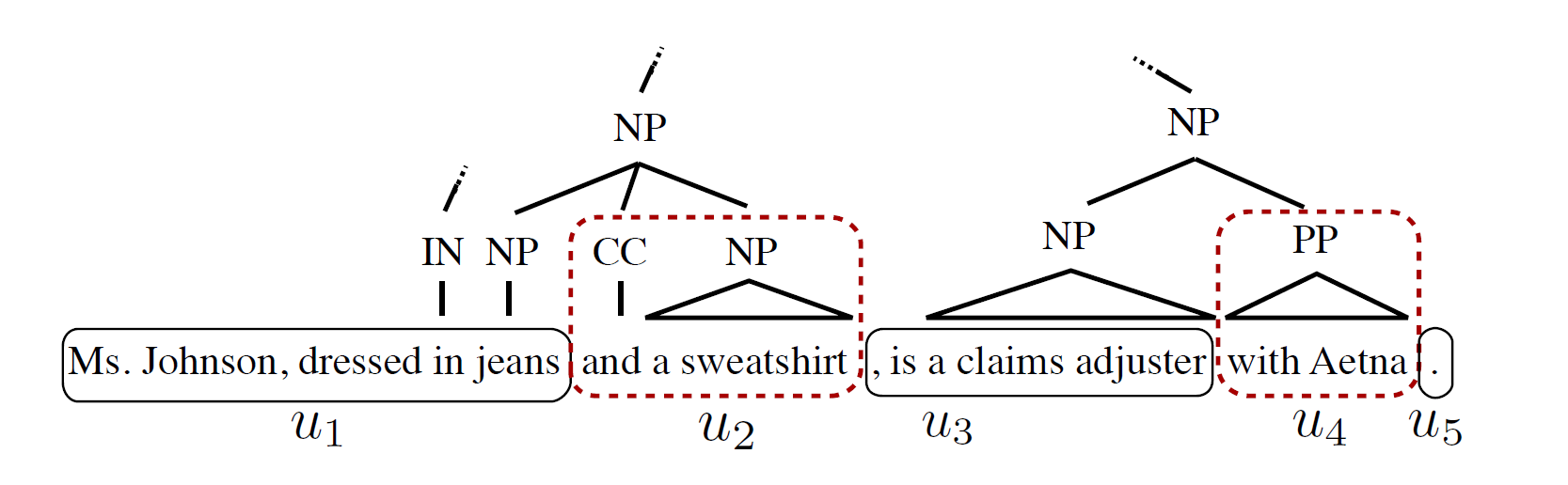
比如上图的语法树,如果删去虚线框的内容,也就是第二个名词短语和介词短语,并不会影响句子的语法通顺,但语义是可能被修改的。
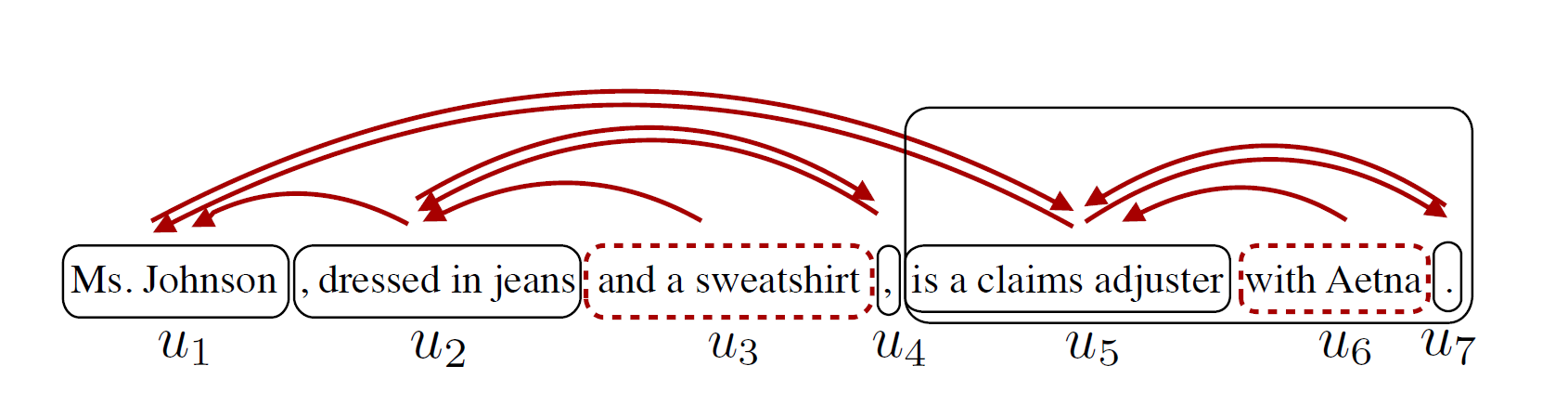
联合压缩也就是将RST和句法两种压缩结合在一起。从上图我们可以看到,貌似句法压缩的分割更细,实际上大多数情况下确实如此:句法分割比RST分割更为细致,基本上都可以在RST分割后的EDU内实现。因此,先进行RST压缩,再进行句法压缩,是可行的。具体的过程是这样的:
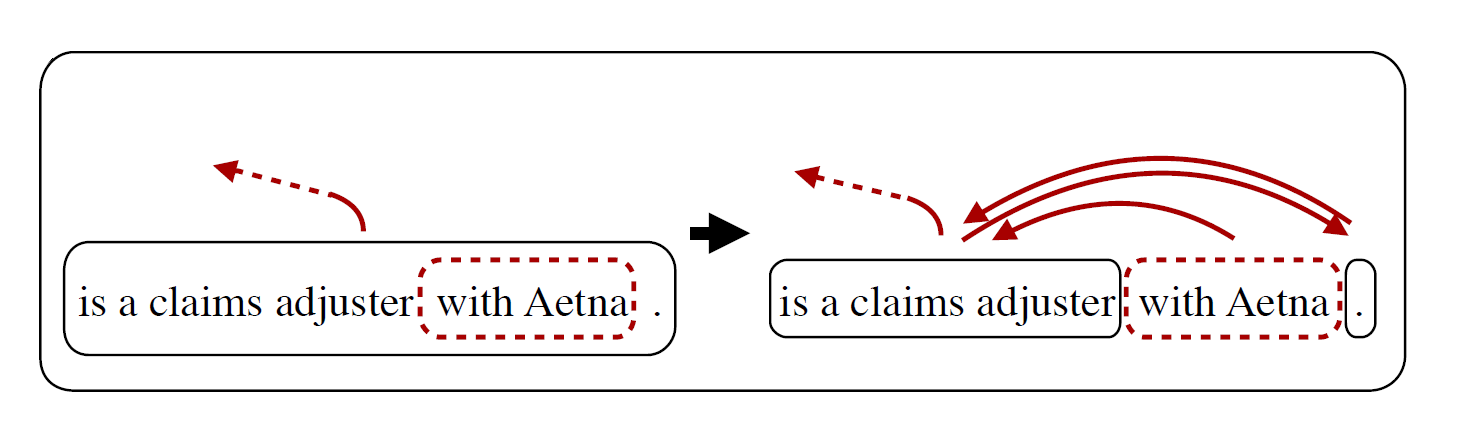
“with Aetna”是一个可能的删除项,它从文本单元中分离出来,并且引入了相应的RST关系。更严谨的定义是这样的,就像之前提过的,RST关系可以整理成关系树:
$$ T{RST} = (S{RST}, \pi_{RST}) $$
其中,( S{RST} ) 是EDU切片 ((i,j));( \pi{RST} ) 是EDU切片集合到幂集的映射 ( S \rightarrow 2^S ) 。可以将EDU切片看做RST关系树的结点,映射构建了父子结点关系。同时,语法树 ( T_{SYN} ) 也可以通过类似的手法构建,但是语法树的通常比修辞树的子树更细致。
假定 ( T{SYN(kl)} ) 是语法树 ( T{SYN} ) 的非平凡子树,并且完全包含在一个EDU切片 ( (i, j) ) 中。这样,可以通过修辞树的扩张来定义联合压缩树:
$$ S{COMB} = S \cup S{SYN(kl)} \cup {(i,k), (l,j)} $$
$$ \pi{COMP} = \pi{RST} \cup \pi_{SYN(kl)} \cup { (i,k) \rightarrow (l,j), (l,j) \rightarrow (i,k),(l,k) \rightarrow (i,k) } $$
结合上面一个例子进行更详细的阐释:除了EDU ( (i, j) ) = “is a claims adjuster | with Aetna | .” 以外,现存修辞树的其余部分都完好地保存。而 ( (i, j) ) 在语法树的框架下分裂成三份 (u_5, u_6, u_7) ,其中 (u_5) 和 (u_7) 相互依存,(u_6) 依赖于前后两者。将修辞树中所有的子树替换成可以替换的语法树中的最大子树,就完成了联合压缩。
代词对应限制 - Anaphora Constraints
在摘要中非常重要的跨句的连贯性(cross-sentential coherence)是代词的前后呼应。在没有加以代词限制的情况下,60%左右摘要结果会出现孤零零的代词,它们的前词(antecedent)都消失了。这样指代不清的错误对于摘要而言是非常严重的问题,所以需要加代词限制。
代词替换 - Pronoun Replacement
直接将代词替换成它所指代的前词,就可以避免前词消失的问题。
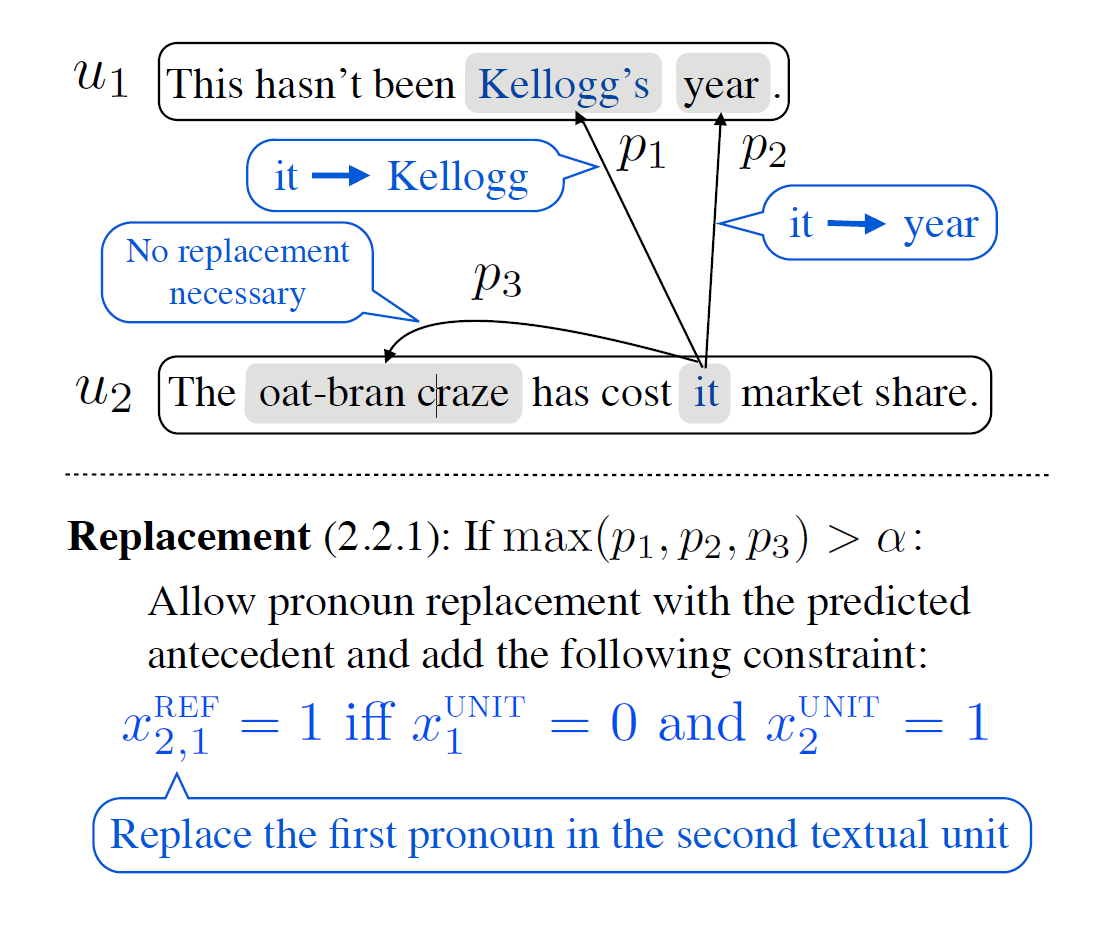
在实际操作中,他们跑了Berkeley Entity Resolution System并且计算了所有可能前词的指代可能性。假若指代系统能够确定,所有可能的最大概率超过了阈值: ( \max (p_1, p_2, p_3) = p_1 > \alpha ),在上图中就是 “Kellogg” ,就允许“Kellogg”替换代词。并且,量化规则是这样的:
$$ \forall j \; x_{ij}^{REF} = 1 $$
当且仅当第 (i) 个句子中的第 (j) 个代词在摘要前文中没有对应词时进行替换
由于展开了代词的指代对象,所以长度限制也应该被调整。
前词限制 - Pronoun Antecedent Constraints
代词替换之危险在于,如果指代系统做出了错误的预测,那么替换之后的语义就完全错误了。比较好运的是这样的情况少有发生,优化的比较好。但是,也可以采用更保守的策略,就是在摘要中加入额外的信息而非直接替换,将判断交给人类读者。
这个策略要求将代词所有可能的指代对象都包括到摘要中。当然这指代对象前词的可能性也需要超过一个阈值 (\beta)。

量化形式是这样的:
$$ \forall i,k \; x{i}^{UNIT} \le x{k}^{UNIT} $$
如果 (u_i) 在代词映射意义上依存于 (u_k)
特征与权重 - Features and Weights
特征( \mathbf{f}(\bullet) ) 和权重参数 (\mathbf{w}^T)是从学习中得到的。例如对于代词对应问题,特征有词汇(Lexical),结构(Structural),聚合(Centrallity)等等特征。包括多次重复出现的词汇,文本单元的位置、长度,一组词汇与句子的编号,借用指代系统发现的呼应关系等等,论文中没有给出明确的定义。
评价与训练 - Evaluation and Training
评价采用ROUGE与人工相结合的方式。
实验预处理 - Experiment Preprocessing
先用GPU加速的分词器Berkeley Parser,和分析指代、语句连接的解析系统Berkeley Entity Resolution System对所有的数据进行处理。此外,用根据RST Treebank训练的条件随机场semi-Markov CRF(Conditional Random Fields)来将文本分割为EDU。其中RST Treebank的边界、短片段的长度和标识都有特征。另外,通过一系列对话语分词的优化方法,UCB组的分词准确率略高于Yoshida。