apache kylin
Apache kylin 技术报告
Extreme OLAP Engine for Big Data
赵阳旻, 14307130067
Introduction
kylin是什么?
kylin是第一个完全由中国团队独立开发的apache顶级项目。kylin是一个基于Hadoop的分布式分析引擎,它可以通过SQL接口,提供超大数据集的多维分析(OLAP)。
亚秒级查询
亚秒级查询是kylin最主要的技术特点。这个特点是通过如下操作实现的:
- 确定
Hadoop上的一个星型模式的数据集 - 构建数据立方体
- 可通过
JDBC,REST API等接口查询相关数据
为什么引入kylin?
引入kylin的目的就是提供Hadoop上超大数据规模的亚秒级SQL查询。相对于HIVE的离线分析,kylin可做到实时查询,并且时间延迟低很多。
数据模型视角

从数据模型视角来看,kylin的结构如图所示:
- Star Schema
对于终端的程序员而言,他们面对的直接是存储在HIVE中的源数据。这里要特别注意,源数据是按照星形模式存储的。之所以强调这一点,是因为之后在kylin构建数据立方体时要用到。 CubeMetadata
kylin的元数据是通过map-reduce构建得到的,这部分元数据对于kylin集群而言至关重要。同时,它们是对程序员透明的!作为程序接口的使用者是不会接触到kylin的底层元数据的。当他们通过REST API或JDBC操作kylin时,就好像直接在HIVE上操作一样,同时会感觉到数据分析加快了许多。HBaseStorage
kylin的元数据会储存在HBase中,特别是数据立方体。数据立方体的源数据从HIVE中读出以后,经过数据立方体(Cube)建立,会以HFile的形式保存在HBase中。
数据立方体
为了透彻地理解kylin系统,首先需要了解一下它背后的数据载体,也就是数据立方体。
数据立方体和关系型数据库一样,是一种数据的存储逻辑。但有别于关系型数据库的是,数据立方体可以从多角度进行数据查询和分析。
事件的记录
数据立方体用两张表来记录一个事件:
事实表
记录事件的要素维表
给出详细的记录
下面这张图给出了一个具体的例子:
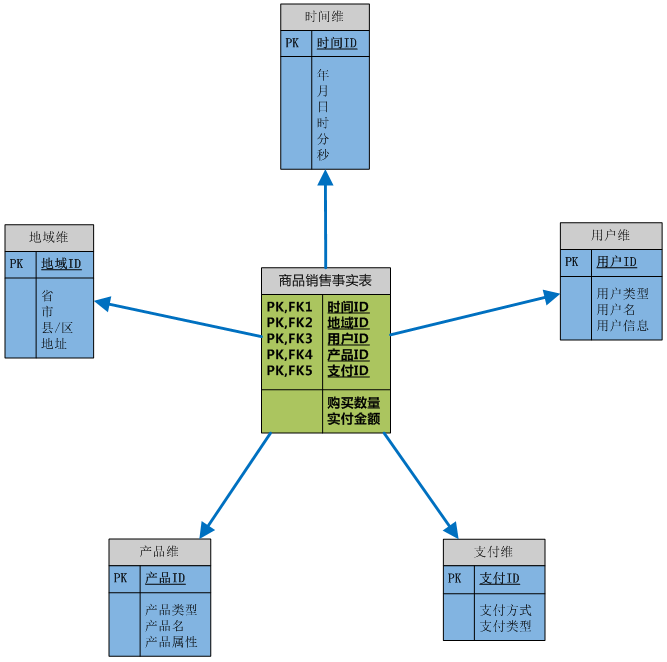
这张图描述了一个具体的数据立方体中的事件。在它的事实表中记录了两类属性:
- 维度
- 度量
维度是如时间、地域、产品之类的宽泛的描述,它不具有任何具体的信息。度量则是如购买数量、实付金额这一类的由聚合函数构成的计算值,它代表了当前维度下的度量值。
实际上事实表中的维属性是一个关联到维表的键,它关联到具体的维度表。然有由维度表给出更细粒度的分类以及具体的数值。
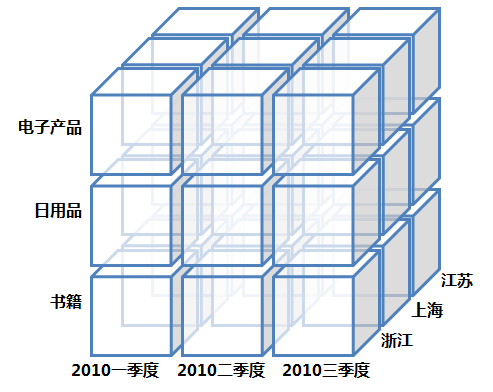
星型模式的图对于“数据立方体”这个说法的展现还不够明显,可以参考下面这张图:它有产品、地域、时间三个维度,每个维度上具有不同的值,它们构成了一个数据立方体。
OLAP
OLAP是数据立方体的操作。我们知道,关系型数据库是以关系代数为基础进行操作的。同样,在数据立方体中,则依靠于OLAP,即Online Analytical Processing,其中文含义为联机分析处理。
实际上我们也可以看到kylin自我标榜为一个OLAP引擎:Extreme OLAP Engine for Big Data.
典型应用场景
OLAP既然是基于数据立方体的操作集合,那么它的应用场景也和数据立方体相关。一个典型的OLAP与数据立方体的应用场景是这样的:
- 多维的数据展现方式
- 较高的查询效率
甚至能支持百万千万数量级的查询 - 灵活的分析
可以从不同角度不同层面对数据进行细分和汇总
与OLTP的差别
OLAP和OLTP永远是不同的,它们的主要差别可以用下面这张表来概括:
| 数据处理类型 | OLTP |
OLAP |
|---|---|---|
| 面向对象 | 业务开发人员 | 分析决策人员 |
| 功能实现 | 日常事务处理 | 面向分析决策 |
| 数据模型 | 关系模型 | 多维模型 |
| 数据量 | 几条或几十条记录 | 百万千万条记录 |
| 操作类型 | 查询、插入、更新、删除 | 查询为主 |
OLAP的操作
下图概要地描述了OLAP的操作
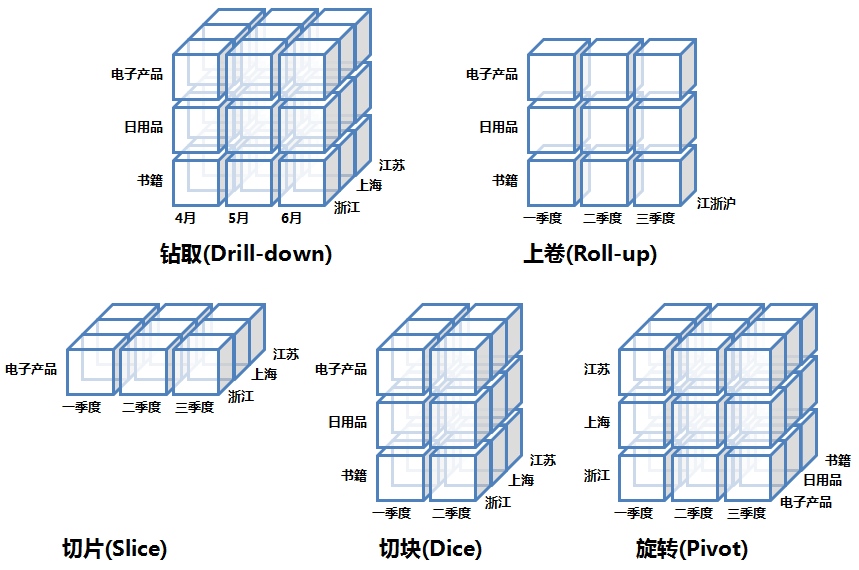
- 钻取(Drill-down)
在维的不同层次间的变化,从上层降到下一层,或者说是将汇总数据拆分到更细节的数据,比如通过对2010年第二季度的总销售数据进行钻取来查看2010年第二季度4、5、6每个月的消费数据。
- 上卷(Roll-up)
钻取的逆操作,即从细粒度数据向高层的聚合,如将江苏省、上海市和浙江省的销售数据进行汇总来查看江浙沪地区的销售数据。
- 切片(Slice)
选择维中特定的值进行分析,比如只选择电子产品的销售数据,或者2010年第二季度的数据。
- 切块(Dice)
选择维中特定区间的数据或者某批特定值进行分析,比如选择2010年第一季度到2010年第二季度的销售数据,或者是电子产品和日用品的销售数据。
- 旋转(Pivot)
即维的位置的互换,就像是二维表的行列转换,如图中通过旋转实现产品维和地域维的互换。
OLAP的优势
从之前的简要介绍中我们可以发现,OLAP的明显优势在于:
- 分析:从不同的角度灵活分析
- 查询:跨表的查询不需要进行复杂的关系代数
OLAP的问题,为什么我们需要kylin?
对kylin最直接的需求还是出于数据量。传统OLAP的容量不足以支撑大规模的数据分析,在每天有千万、数亿条的数据量,并提供若干维度的分析模型的情况下,传统的OLAP会出现大量实时运算导致的响应时间迟滞。
kylin要解决的问题是就是尽量减小这个延时。或者说是从HIVE中读到的源数据转换成数据立方体的延时。所以,kylin是HIVE加速器,也是OLAP引擎。
Apache kylin的核心概念
kylin的核心概念有:
- Table
- Model
CubeCube Segment- Job
这些核心概念是构成kylin算法、存储的基础。
Table
表定义在HIVE中,是数据立方体的数据源,在建立数据立方体之前,必须同步在kylin中。Model
模型描述了一个星型模式的数据结构,它定义了一个事实表和多个维度表的连接关系Cube
定义了使用的模型、模型中的表的维度、度量(聚合函数)Cube Segment
它是立方体构建(build)后的数据载体。一个segment映射HBase中的一张表,立方体实例构建后,会产生一个新的segment,一旦某个已经构建的立方体的原始数据发生变化,只需刷新(fresh)变化的时间段所关联的segment即可。这是一种增量式的构建数据立方体的方法,也对应于kylin最新的快速立方体算法(fast cubing algorithm)。Job
立方体实例发出构建请求后产生。它的状态标志数据立方体实例的构建状态:- 作业执行的状态信息为
RUNNING表明立方体实例正在被构建 - 作业状态信息为
FINISHED表明立方体实例构建成功; - 作业状态信息为
ERROR表明立方体实例构建失败
- 作业执行的状态信息为
Apache kylin的架构
kylin的架构如图所示:
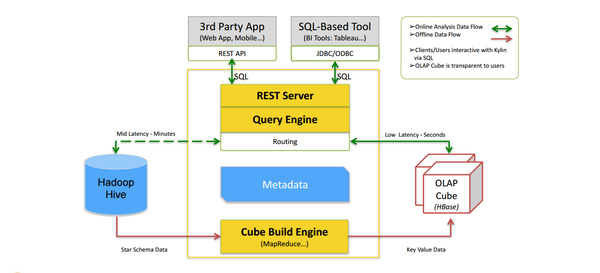
- 数据立方体构建引擎
计算数据立方体
- Rest Server
当前kylin采用的REST API、JDBC、ODBC接口提供web服务。
- 查询引擎
Rest Server接收查询请求后,解析SQL语句,生成执行计划,然后转发查询请求到HBase中,最后将结构返回给 Rest Server。
预计算
为什么说kylin是一个HIVE加速器?或者说kylin是怎么做到加速的?这个问题的解答就是kylin的核心思想:预计算。
kylin的预计算是针对一个星型拓扑结构的数据立方体,进行多个维度组合的度量的计算。预计算的结果会保存在HBase中,这个过程就是数据立方体的建立过程。下面这张图概括性地描述了Map Reduce预计算的模块与kylin的架构:
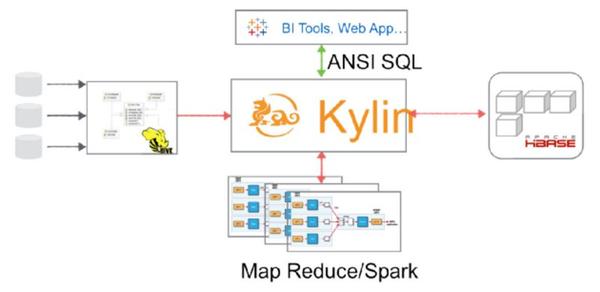
kylin先后采用了By Layer Cubing 和 Fast Cubing 两种算法进行预计算。
By Layer Cubing
By Layer Cubing是kylin最早采用的数据立方体算法:分层式地构建。下面这张图描述了这个算法的流程:
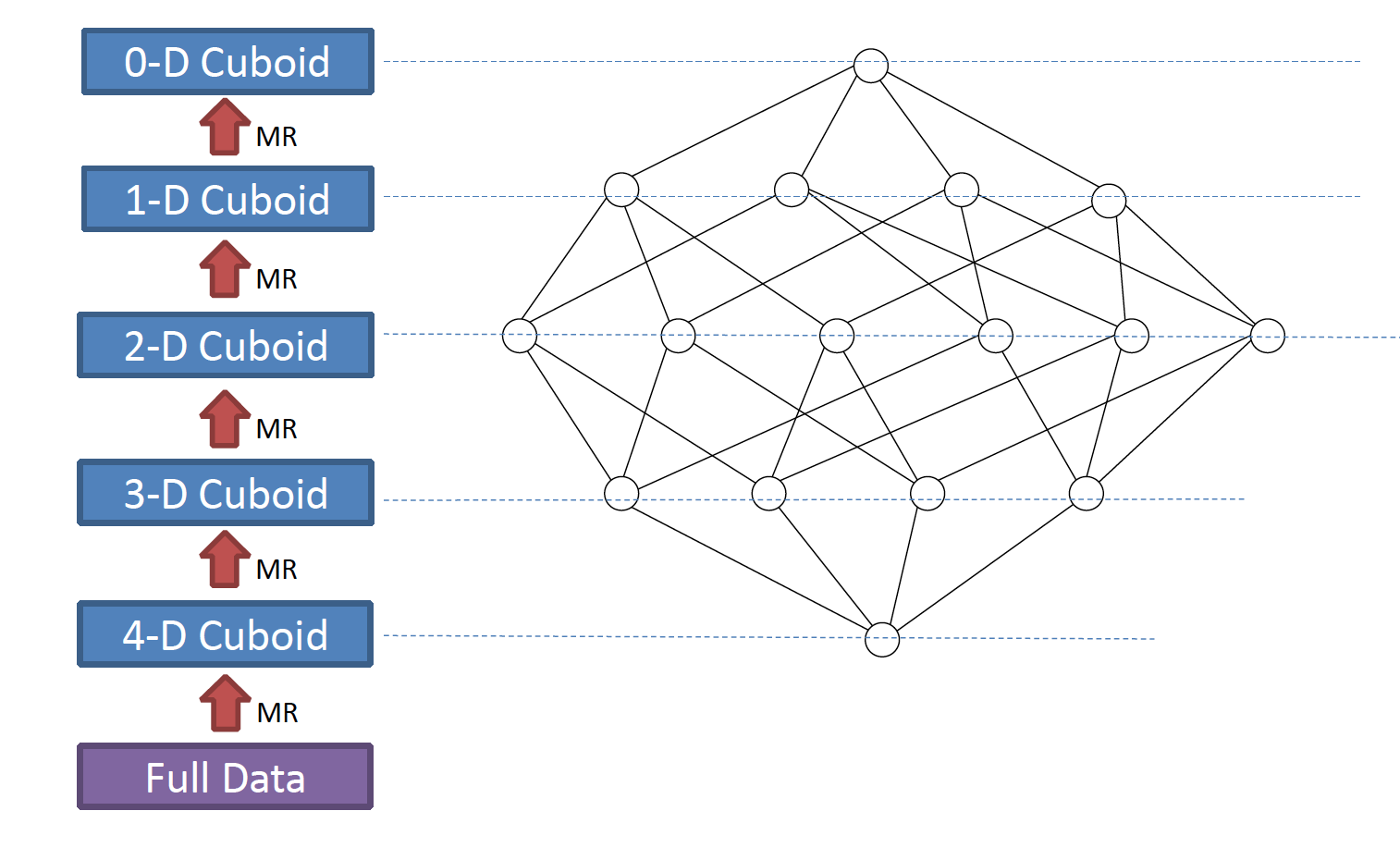
可以看到,对于一个N维的立方体,kylin要进行N次串行的Map Reduce计算。在这个算法中,Map-Reduce的key-value对是这样组成的:
key由维度的组合的构成value由度量的组合构成
N维的数据立方体会有N个维属性,kylin会选择一个维度进行聚合计算的Map Reduce。这样就可以得到一个N-1维的子立方体(Cuboid)。通过这种迭代的方式,令每一层的子立方体基于其父立方体计算value,就可以最终计算出整个数据立方体的度量。
下面这张图描述了一个详细的计算过程:

最左边是HIVE中的源数据,最右边是HBase中保存的数据立方体的表,中间两列则是分层的Map Reduce计算过程。可见,kylin首先会聚合属性,计算度量,然后将数据Map到一起,接着Reduce计算出度量的结果。
这种算法背后的哲学是:用空间换时间。实际上,在关系型数据库中采用了索引index的管理方式,也是一种空间换时间的策略。但是在数据立方体这里,这个哲学原则被执行得更为彻底:kylin将所有可能的维度组合对应的度量都计算出来了,并且保存在HBase之中。
如此一来,当应用程序需要分析某个维度组合的度量值时,kylin需要做的不是从HIVE中进行计算,而是从HBase中直接取出度量结果。
By Layer Cubing的问题
在开发人员的实践中,发现了By Layer Cubing算法的一些问题:
- IO率高
由于每一层计算的输出会用做下一层计算的输入,这些key-value需要写到HDFS上;当所有计算都完成后,kylin还需要额外的一轮任务将这些文件转成HBase的HFile格式,以导入到HBase中去。
- 串行mapreduce
当维度很多时,Hadoop的开销也很可观。
Fast Cubing
为了解决By Layer Cubing算法的问题,开发人员提出了新的算法:快速立方体(Fast Cubing):
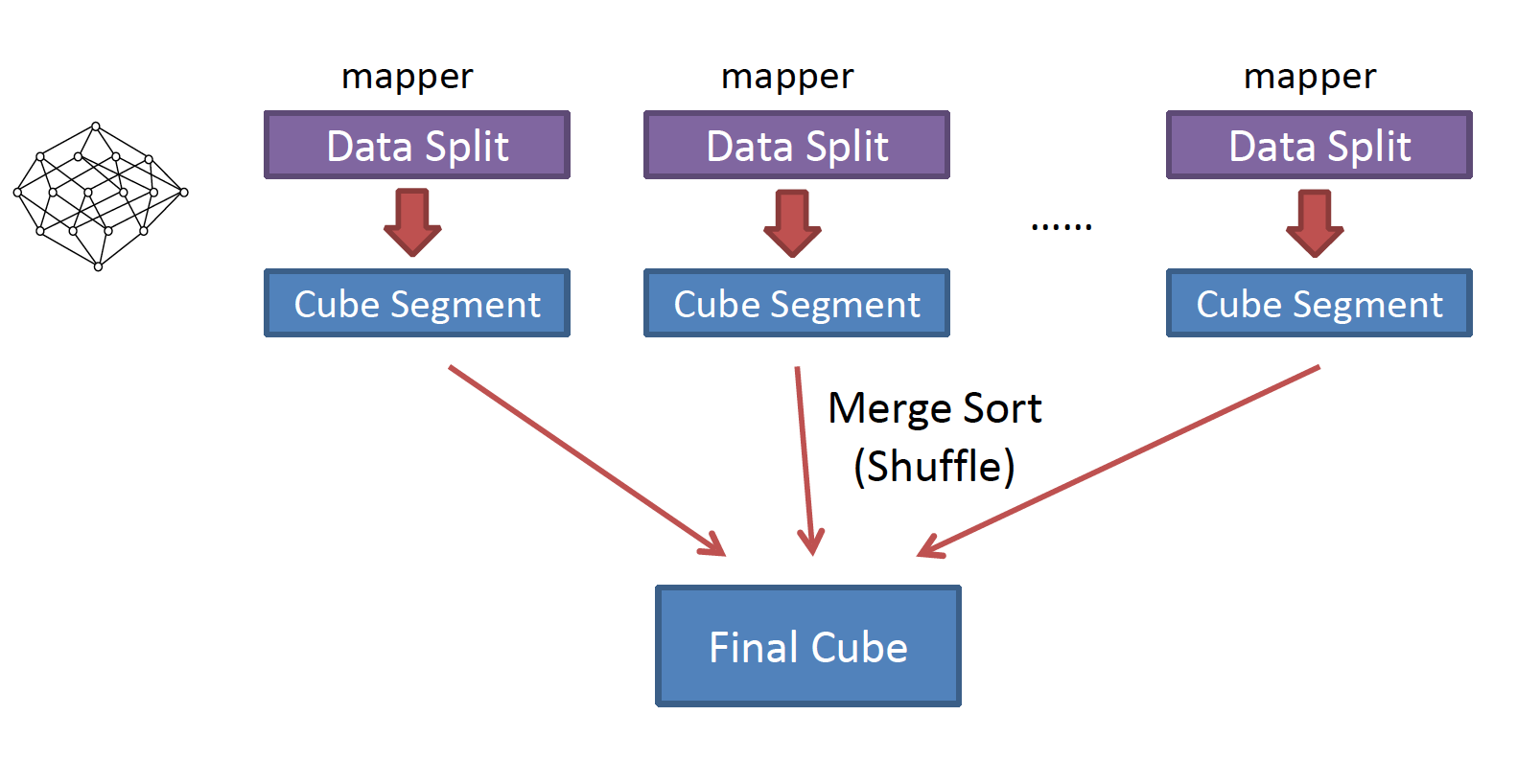
如上图,新算法对Mapper所分配的数据块,将它计算成一个完整的小立方体段(Cube Segment);每个Mapper将计算完的立方体段输出给Reducer做合并,生成大立方体,也就是最终结果。
相比于旧算法,新算法的特点是:
- 利用Mapper端的CPU和内存进行预聚合
这实际上是一个distinct操作,如此Mapper输出的每个key都是不同的,这样会减少输出到Map Reduce的数据量
- 只需要一次Map Reduce
新算法将需要的数据块组合全都做计算后再输出给Reducer,由Reducer再做一次合并merge计算出完整数据的所有组合
可以从kylin的源代码中看到,最新版本的kylin采用的是段式增量的数据立方体构建,也就是Fast Cubing:
|
|
计算立方体之后
在完成立方体的预计算后,kylin要将Reducer输出的子立方体数据转化成HBase中的HFile,并将HFile 加载到HBase表中便于查询。在HBase中的HFile将会是如下形式:
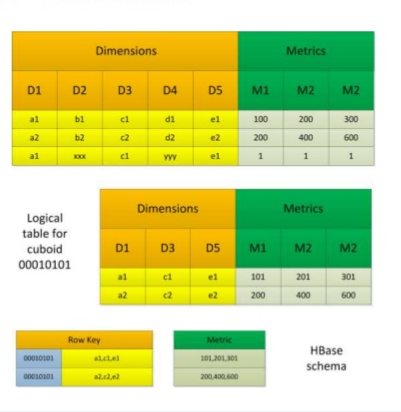
其中rowkey由维度组合而成,维度组合对应的度量值则构成了column family。
同时,为了查询减少存储空间,会对rowKey和column family的值进行编码,默认编码是Snappy。
查询引擎
kylin采用了第三方模块——calcite来进行SQL的分析,因为calcite具有以下特性:
- 支持标准
SQL - 物化视图
- 支持星型模式
Slow Query SQL
尽管OLAP功能是亚秒级别的,但有时候仍然需要记录执行结果很慢的SQL语句。此时,一个后台线程BadQueryDetector会不断去发现前端请求的错误的SQL语句,它的主要代码是这样的:
public void run() {
while (true) {
try {
Thread.sleep(detectionInterval);
} catch (InterruptedException e) {
// stop detection and exit
return;
}
try {
detectBadQuery();
} catch (Exception ex) {
logger.error("", ex);
}
}
}
其中detectBadQuery()是这样的:
private void detectBadQuery() {
long now = System.currentTimeMillis();
ArrayList<Entry> entries = new ArrayList<Entry>(runningQueries.values());
Collections.sort(entries);
// report if query running long
for (Entry e : entries) {
float runningSec = (float) (now - e.startTime) / 1000;
if (runningSec >= alertRunningSec) {
notify("Slow", runningSec, e.startTime, e.SQLRequest.getProject(), e.SQLRequest.getSQL(), e.thread);
dumpStackTrace(e.thread);
} else {
break; // entries are sorted by startTime
}
}
// report if low memory
if (getSystemAvailMB() < alertMB) {
logger.info("System free memory less than " + alertMB + " MB. " + entries.size() + " queries running.");
}
}
可以看到,这里kylin检查了两样对象:
alertMB
当系统可用内存小于alertMB时,进行一些错误处理。
alertRunningSec
当SQL的执行时间大于alertRunningSec,kylin将其定性为slow query SQL。
所谓的“坏”查询具体是这样的:
|
|
可见系统内存的限制是100MB。对于alertRunningTime的阈值则可以在配置文件中设置:
|
|
默认情况下是90秒。
元数据
kylin的元数据包括:
- 立方体描述(
Cubedescription) - 立方体实例(
Cubeinstances) - 项目(project)
- 作业(job)
- 表 (table)
- 字典 (dictionary)
在kylin集群中至关重要,假如元数据丢失,kylin集群将无法工作。元数据在kylin中的储存也有两种模式:
- 在
HBase中储存 - 在本地文件系统中储存
在HBase中储存
kylin默认将元数据存在HBase中,这可以通过配置文件${kylin_HOME}/conf/kylin.properties观察得到:
kylin.metadata.url=kylin_metadata@hbase
kylin_metadata@HBase表示,元数据存储在HBase中的kylin_metadata表中。相应的存储方法如下:
|
|
但是当key-value对的value大于一个最大值kvSizeLimit时,数据将被保存在HDFS中:
|
|
kvSizeLimit的大小十分重要,因为kylin为了提高整体性能将HBase中的元数据缓存在HBase内存中:

由于kylin的数据立方体构建是增量式的,所以HBase表会越来越大。假如不及时清理历史数据,将会使HBase的进程发生OutOfMemoryError错误。
在本地文件系统中储存
将kylin.metadata.url指向本地文件系统的一个绝对路径:
kylin.metadata.url=/home/${username}/${kylin_home}/kylin_metada
架构回顾
最后,再回顾一下kylin的总体架构:
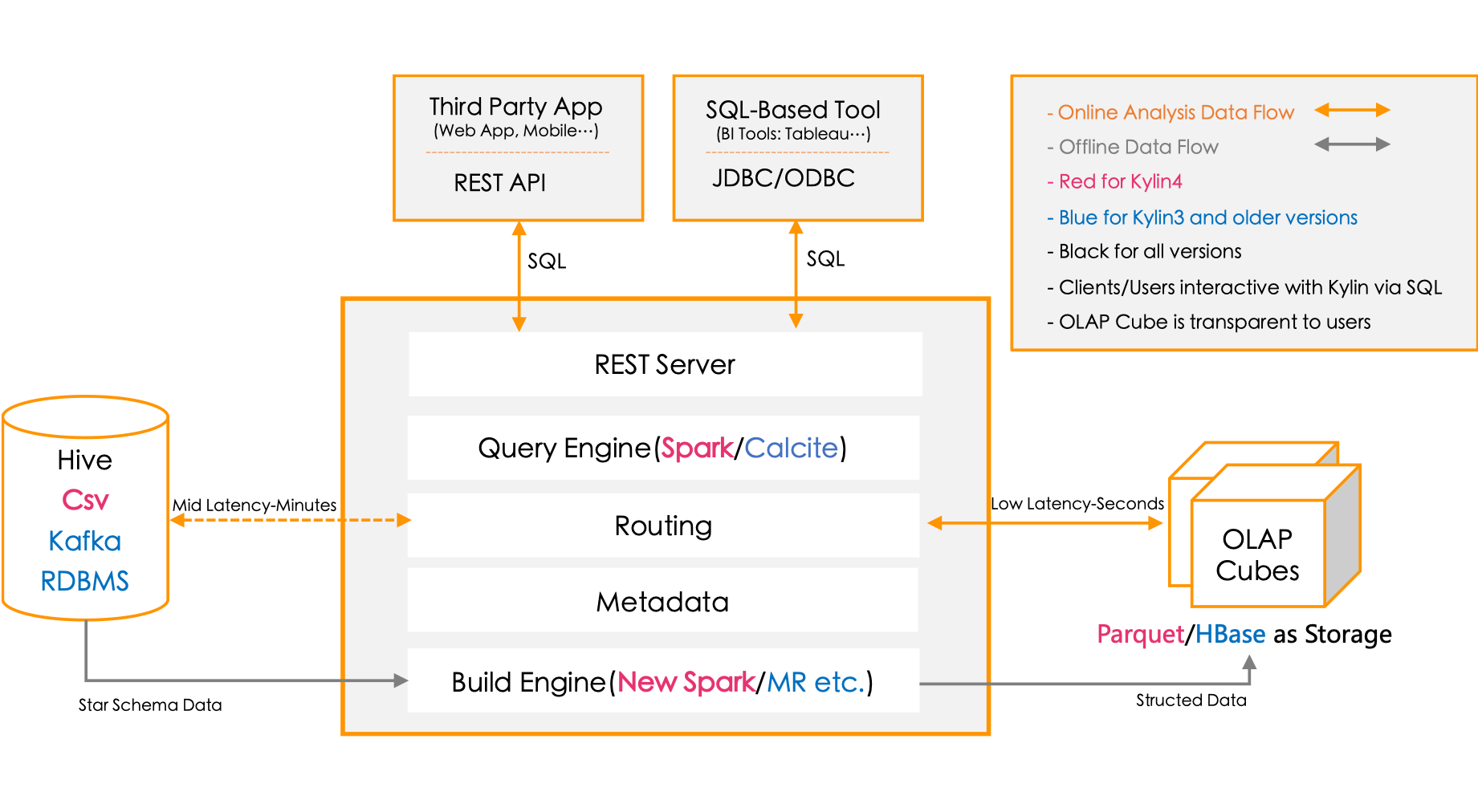
- 应用层
REST APIJDBC/ODBC
这两类接口可以返回标准化的查询,然后交给查询引擎处理
kylin对应用提供了以上两类接口。
- 查询引擎
查询引擎集成了calcite,会分析应用层传来的标准SQL语句,并将生成kylin自己的计划。同时,在查询任务执行时,会启动检测线程去检查SQL的执行情况,判断其是否是不良的查询。
- 路由
对于一个分析查询请求,kylin首先会到HBase中找数据立方体的度量。如果存在请求的维度组合与度量,则从HBase中返回相应的度量,这个过程是快的。但是如果相应的目标不存在,那么kylin还是会回到Hadoop HIVE去进行数据分析、计算,这个过程相对较慢。
- 数据立方体构建引擎
- 元数据
数据立方体引擎根据HIVE中的源数据预计算数据立方体,并作为元数据保存到HBase中。